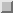Вычислительный центр им. А.А. Дородницына РАНРаздел виртуального курса
|
|
|---|
Вычислительный центр им. А.А. Дородницына РАНРаздел виртуального курса
|
|
|---|
Коллективная коммуникация вовлекает все процессы в коммуникаторе. (Коммуникаторы были введены в модуле по основам MPI программирования .) Цель коллективной коммуникации состоит в том, чтобы управлять "общим" куском или набором информации. Функции коллективной коммуникации были построены при использовании функций попарной коммуникации. Вы можете строить ваши собственные функции коллективной коммуникации, но это повлечет много утомительной работы и не будет столь же эффективно.
Хотя другие библиотеки передачи сообщений предоставляют некоторые вызовы коллективных коммуникаций, ни одна из них не обеспечивает набор функций коллективной коммуникации столь же полный и надёжный в эксплуатации, как предоставленные библиотекой MPI. В этой лекции мы вводим эти функции в трех категориях: синхронизация, перемещение данных и глобальные вычисления.
Функции MPI для коллективной коммуникации отличаются по разным признакам от функций MPI для попарной коммуникации, котрые были введены в модуле MPI попарный обмен сообщениями I. Вот - особенности (характеристики) функций коллективной коммуникации MPI :
Коллективные коммуникации MPI можно разбить на три подмножества: синхронизация, перемещение данных и глобальные вычисления, которые охвачены в следующих трех параграфах.
MPI_Barrier |
(MPI_Comm comm) |
где:
MPI_Comm |
является предопределенной структурой MPI для коммуникаторов, а |
comm |
- некий коммуникатор. |
Теперь давайте посмотрим на функциональные возможности и синтаксис этих функций.
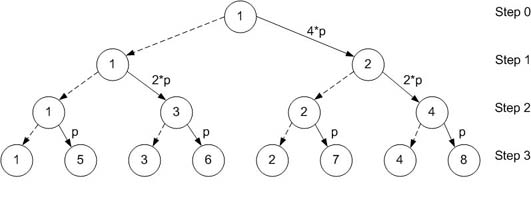
int MPI_Bcast |
(void* buffer, int count, MPI_Datatype
datatype, int root, MPI_Comm
comm) |
где:
buffer |
- стартовый адрес буфера, |
count |
- целое число, указывающее число элементов данных в буфере, |
datatype |
- определенная константа MPI, указывающая тип элементов данных в буфере, |
root |
является целым числом, указывающим ранг корневого процесса широкого распространения, и |
comm |
является коммуникаторм.. |
Функция MPI_Bcast нужно вызвать каждым узлом группы, определяя те же самые
comm и root.
Сообщение отправляется из корневого процесса ко всем процессам в группе, включая корневой процесс.
int MPI_Gather |
(void* sbuf, int scount, MPI_Datatype
stype, void* rbuf, int rcount,
MPI_Datatype rtype, int root, MPI_Comm
comm ) |
int MPI_Scatter |
(void* sbuf, int scount, MPI_Datatype
stype, void* rbuf, int rcount,
MPI_Datatype rtype, int root, MPI_Comm
comm) |
где, для функции Gather:
sbuf |
- стартовый адрес буфера отправителя, |
scount |
- число элементов в буфере отправки, |
stype |
- тип данных элементов буфера отправки, |
rbuf |
- стартовый адрес буфера получателя, |
rcount |
- число элементов для любого единственного получателя, |
rtype |
- тип данных элементов буфера получателя, |
root |
- ранг процесса получателя и |
comm |
- коммуникатор. |
и для функции Scatter:
sbuf |
- адрес буфера отправителя, |
scount |
- число элементов, отправленных каждому процессу, |
stype |
- тип данных элементов буфера отправителя, |
rbuf |
- адрес буфера получателя, |
rcount |
- число элементов в буфере получателя, |
rtype |
- тип данных элементов буфера получателя, |
root |
- ранг процесса отправителя и |
comm |
- коммуникатор. |
В операции сборки (gather), каждый процесс (включяя корневой процесс) отправляет scount элементов типа stype из sbuf к корневому процессу. Корневой процесс получает сообщения и запоминает их в порядке рангов в rbuf. Для размещения-рассеивания (scatter) верно обратное. Корневой процесс отправляет буфер из N кусков данных (N = числу процессов в группе) так, чтобы процесс 1 получил первый элемент, процесс 2 получил второй элемент, и т.д.
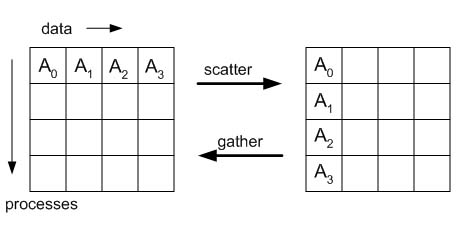
Следующий пример для gather (сборки "каждый-одному") добавляет понимание этого рисунка.
double a[100,25],b[100],cpart[25],ctotal[100];
int root;
root=0;
for(i=0;i<25;i++)
{
cpart[i]=0;
for(k=0;k<100;k++)
{
cpart[i]=cpart[i]+a[k,i]*b[k];
}
}
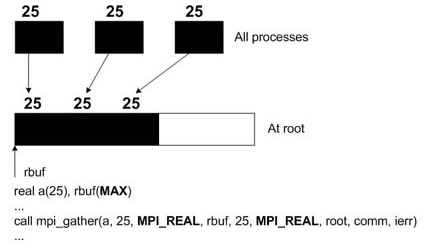
MPI_Gather(cpart,25,MPI_REAL,ctotal,25,MPI_REAL,root,MPI_COMM_WORLD);
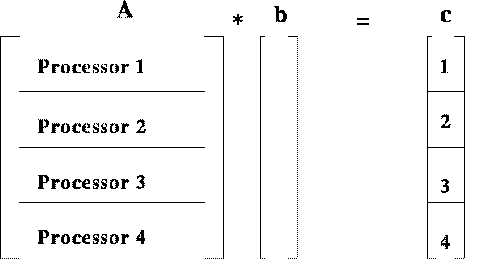
b: вектор совместного использования всех процессов
c: вектор, обновленный каждым процессом независимо
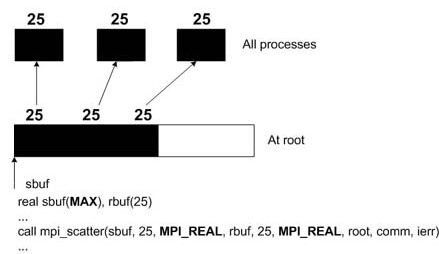
Нетрудно представить себе аналогичные фрагменты на С.
Функции MPI_Gatherv и MPI_Scatterv - это версии MPI_Gather и MPI_Scatter с переменным размером сообщений. MPI_Gatherv расширяет функциональность MPI_Gather изменяя получаемое число от целого числа до массива целых чисел и предоставив новый аргумент displs (тоже массив). MPI_Gatherv допускает переменное число данных от каждого процесса и допускает немного гибкости по поводу того, куда помещать собранные данные, также в корень. Как двойник MPI_Gatherv, MPI_Scatterv - расширение MPI_Scatter в тех же самых отношениях, как MPI_Gatherv к MPI_Gather. Чуть больше информации по этой темы предоставлено в модуле MPI коллективный обмен сообщениями II.
int MPI_Gatherv |
(void* sbuf, int scount, MPI_Datatype
stype, void* rbuf int *rcount, int*
displs, MPI_Datatype rtype, int root,
MPI_Comm comm) |
int MPI_Scatterv |
(void* sbuf, int* scount, int*
displs, MPI_Datatype stype, void* rbuf,
int rcount, MPI_Datatype rtype, int root,
MPI_Comm comm) |
Переменные для Gatherv таковы:
sbuf |
- стартовый адрес буфера отправителя, |
scount |
- число элементов в буфере отправки, |
stype |
- тип данных элементов буфера отправки, |
rbuf |
- стартовый адрес буфера получателя, |
rcount |
- массив, содержащий число элементов, которые будут получены от каждого процесса, |
displs |
- массив, задающий смещение относительно rbuf (стартового адреса буфера получателя), в который помещаются входящие данные от соответствующего процесса, |
rtype |
- тип данных буфера получателя, |
root |
- ранг процесса получателя, |
comm |
- коммуникатор группы. |
Переменные для функции Scatterv таковы:
sbuf |
- адрес буфера отправителя, |
scount |
- массив целых чисел, определяющий число элементов для отправки каждому процессу, |
displs |
- массив, определяющий смещение относительно sbuf, от которого берутся данные отправляемые к соответствующим процессам, |
stype |
- тип данных элементов буфера отправителя, |
rbuf |
- адрес буфера получателя, |
rcount |
- число элементов в буфере получателя, |
rtype |
- тип данных элементов буфера получателя, |
root |
- ранг процесса отправителя и |
comm |
- коммуникатор группы |
С целью иллюстрации использования функций MPI_Gatherv и MPI_Scatterv, дадим ниже два фрагмента программ на ФОРТРАНе:
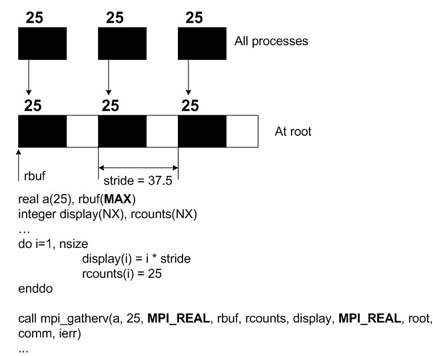
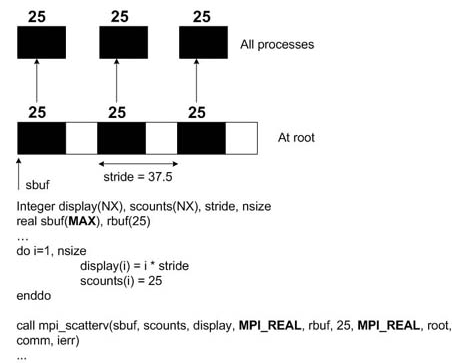
Нетрудно представить себе аналогичные фрагменты на С.
О MPI_Allgather можно думать как об MPI_Gather, где все процессы, а не только корневой, получают результат. Блок j-й буфера получателя - блок данных, отправленный от процесса j. Подобные отношения верны для MPI_Allgatherv и MPI_Gatherv. Синтаксис MPI_Allgather и MPI_Allgatherv подобен MPI_Gather и MPI_Gatherv, соответственно. Однако, аргумент корень отброшен у MPI_Allgather и MPI_Allgatherv.
int MPI_Allgather |
(void* sbuf, int scount, MPI_Datatype
stype, void* rbuf, int rcount,
MPI_Datatype rtype, MPI_Comm comm )
|
int MPI_Allgatherv |
(void* sbuf, int scount, MPI_Datatype
stype, void* rbuf, int* rcount, int*
displs, MPI_Datatype rtype, MPI_Comm
comm) |
Переменные функции Allgather:
sbuf |
- стартовый адрес буфера отправителя, |
scount |
- число элементов в буфере отправки, |
stype |
- тип данных элементов буфера отправки, |
rbuf |
- стартовый адрес буфера получателя, |
rcount |
- число элементов, полученных от любого процесса, |
rtype |
- тип данных элементов буфера получателя, |
comm |
- коммуникатор группы. |
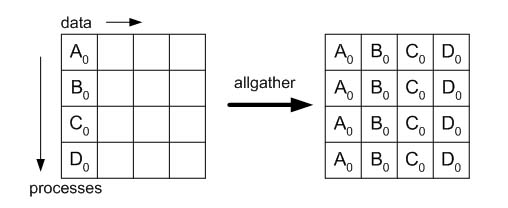
double a[100,25], b[100], cpart[25],
ctotal[100];for(i=0;i<25;i++)
{
cpart[i]=
0;for(k=0;k<100;k++)
{
cpart[i]=cpart[i]+a[k,i]*b[k];
}
}
MPI_Allgather(cpart,25,MPI_REAL,ctotal,25,MPI_REAL,MPI_COMM_WORLD);
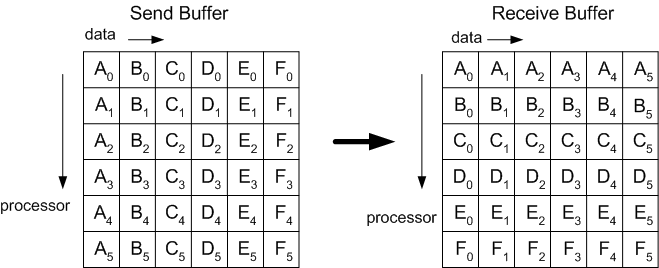
Синтаксис функции MPI_Alltoall таков:
int MPI_Alltoall |
(void* sbuf, int scount, MPI_Datatype
stype, void* rbuf, int rcount,
MPI_Datatype rtype, MPI_Comm comm
) |
Переменный функции Alltoall таковы:
sbuf |
- стартовый адрес буфера отправителя, |
scount |
- число элементов, отправленных каждому процессу, |
stype |
- тип данных элементов буфера отправки, |
rbuf |
- стартовый адрес буфера получателя, |
rcount |
- число элементов, получаемых от любого процесса, |
rtype |
- тип данных элементов буфера получателя, |
comm |
- коммуникатор группы. |
Заметим, чтоте же самые спецификации, что и у Allgather, кроме sbuf, должны содержать scount*NPROC элементов.
2.4 Функции глобальных вычислений
Существует два типа функций глобальных вычислений: приводить (reduce)
и сканировать (scan).
Функция операции, которую передают к функции глобального вычисления
является или предопределенной функцией MPI или функция, предлагаемая пользователем.
MPI обеспечивает четыре функции глобальных вычислений.
Пользователям дана возможность поставлять свои собственные функции.
Вначале этого раздела обсуждается вычисление приведения.
Затем обсуждается вычисление сканирования.
Одна из самых полезных коллективных операций -
глобальное приведение или операция объединения.
Частичный результат в каждом процессе группы объединяется
в одном указанном процессе или всех процессах, используя некоторую желаемую функцию.
Если есть n процессов в группе данного процесса, и D (i, j) - j-ый элемент данных в процессе i,
то элемент данных Dj в корневом процессе,
получаемый из оценки функции приведения дается выражением:
где знак * - функция приведения и она всегда предполагается ассоциативной. Все предопределенные функции MPI также предполагаются коммутативными. Можно определить функции, предполагая их ассоциативными, но не коммутативными. Каждый процесс может предоставлять один элемент или последовательность элементов. В обоих случаях операция объединения выполняется поэлементно на каждом элементе последовательности. Есть три версии приведения. Это - MPI_Reduce, MPI_Allreduce, и MPI_Reduce_scatter. Форма этих примитивов приведения перечислена ниже:
int MPI_Reduce |
(void* sbuf, void* rbuf, int count,
MPI_Datatype stype, MPI_Op op, int root,
MPI_Comm comm) |
int MPI_Allreduce |
(void* sbuf, void* rbuf, int count,
MPI_Datatype stype, MPI_Op op, MPI_Comm
comm) |
int MPI_Reduce_scatter |
(void* sbuf, void* rbuf, int*
rcounts, MPI_Datatype stype, MPI_Op op,
MPI_Comm comm) |
Различия среди этих трех форм приведения:
sbuf |
- стартовый адрес буфера отправителя, |
rbuf |
- стартовый адрес буфера получателя, |
count |
- число элементов в буфере отправки, |
stype |
- тип данных элементов буфера отправки, |
op |
- операция приведения (которой может быть предопределенная в MPI операция или ваша собственная), |
root |
- ранг процесса получателя, |
comm |
- коммуникатор группы.. |
где * - функция приведения, которая может быть либо предопределенной функцией MPI
или определенной пользователем функцией.
Синтаксис функции сканирования MPI таков:
int MPI_Scan |
(void* sbuf, void* rbuf, int count,
MPI_Datatype datatype, MPI_Op op, MPI_Comm
comm) |
sbuf |
- стартовый адрес буфера отправителя, |
rbuf |
- стартовый адрес буфера получателя, |
count |
- число элементов во входном буфере, |
datatype |
- тип данных элементов во входном буфере, |
op |
- операция, |
comm |
- коммуникатор группы. |
Примеры предопределенных операций MPI просуммированы в Таблице 1. MPI также предоставляет механизм для определяемых пользователями операций, используемым в MPI_Allreduce и MPI_Reduce.
| Название | Значение | C-тип | FORTRAN-тип |
|---|---|---|---|
| MPI_MAX | maximum | integer, float | integer, real, complex |
| MPI_MIN | minimum | integer, float | integer, real, complex |
| MPI_SUM | sum | integer, float | integer, real, complex |
| MPI_PROD | product | integer, float | integer, real, complex |
| MPI_LAND | logical and | integer | logical |
| MPI_BAND | bit-wise and | integer, MPI_BYTE | integer, MPI_BYTE |
| MPI_LOR | logical or | integer | logical |
| MPI_BOR | bit-wise or | integer, MPI_BYTE | integer, MPI_BYTE |
| MPI_LXOR | logical xor | integer | logical |
| MPI_BXOR | bit-wise xor | integer, MPI_BYTE | integer, MPI_BYTE |
| MPI_MAXLOC | max value and location | combination of int, float, double, and long double | combination of integer, real, complex, double precision |
| MPI_MINLOC | min value and location | combination of int, float, double, and long double | combination of integer, real, complex, double precision |
int maxht, globmx;
.
.
. (вычисления, которые определяют максимальную высоту)
.
.
MPI_Reduce (maxht, globmx, 1, MPI_INTEGER, MPI_MAX, 0, MPI_COMM_WORLD);
if (taskid == 0) {
.
. (Запись выпуска)
.
}
Простой подход: Один процесс широко распространяет тоже самое сообщение по всем другим процессам, по одному в каждый момент времени.
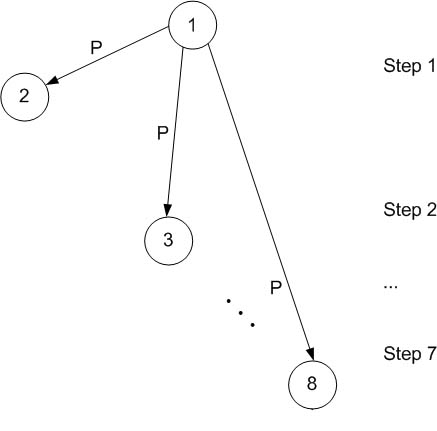
Количество пермещенных данных: (N-1)*p
Более быстрый и остроумный подход: Позвольте другим процессам помочь в размножении сообщения. На первом шаге, процесс 1 отправляет сообщение процессу 2. На втором шаге, оба процесса уже могут участвовать: процесс 1 отправляет сообщение процессу 3, в то время как процесс 2 отправляет процессу 4. Точно так же на третьем шаге, четыре процесса (1, 3, 2, и 4) отправляют сообщение четырем остающимся процессам (5, 6, 7, и 8).
Жирная линия: пересылка данных
Пунктирная линия: проведена по предыдущей передаче
Количество переданных данных: (N-1)*p
Сравните число шагов для этих двух подходов:
Простой подход: N-1
Более быстрый подход: log2N
Последний масштаб улучшается по мере роста N.
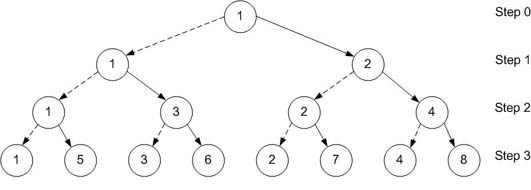
Простой подход: Один процесс размещает N сообщений по другим процессам, по одному в каждый момент времени.
Количество перданных данных: (N-1)*p
Более быстрый подход:
Позвольте другим процессам помочь в размножении сообщения.
В первом шаге процесс 1 отправляет половину данных (размер 4*p) процессу 2.
На втором шаге, оба процесса уже могут участвовать:
процесс 1 отправляет одну половину данных, которые он получил на шаге 1 (размер 2*p) процессу 3,
в то время как процесс 2 отправляет одну половину данных, которые он получил на шаге 1 процессу 4.
На третьем шаге, четыре процесса (1, 3, 2, и 4) отправляют конечные сообщения (размера p)
к оставшимся четырем процессам (5, 6, 7, и 8).
Количество переданных данных: log2N * N * p/2
Сравните число шагов для этих двух подходов:
Простой подход: N-1
Более быстрый подход: log2N
Последний масштаб улучшается по мере роста N
Литература
Книга
Using MPI: Portable Parallel Programming with the Message-Passing Interface, by William Gropp, Ewing Lusk, and Anthony Skjellum. Published 10/21/94 by MIT Press, 328 pages.
World Wide Web
- Домашняя страница MPI в Argonne National Labs http://www.mcs.anl.gov/mpi
- Netlib: MPI
- Параллельные вычисления LAM/MPI
- Модуль Основы программирования в MPI
- Модуль MPI попарные коммуникации I
Выборка программ, доступных на Web, которые иллюстрируют команды, охваченные в этом модуле.
|
© 2003
Вычислительный центр им. А.А.Дородницына
Все права защищены. |
|