Вычислительный центр им. А.А. Дородницына РАНРаздел виртуального курса
|
|
|---|
Вычислительный центр им. А.А. Дородницына РАНРаздел виртуального курса
|
|
|---|
Цель этого краткого модуля состоит в том, чтобы представить Вам некоторые особенности MPI, которые допускают большую гибкость, когда Вы используете коллективные операции MPI, подобные gather (сборке) или scatter (размещению).
MPI_Scatterv, MPI_Gatherv, MPI_Allgatherv, MPI_Alltoallv
Для чего стоит "v"?
- varying (изменение) -- размера, относительного местоположения сообщений
Примеры для обсуждения: MPI_Gatherv и MPI_Scatterv
Можно было бы сказать, что этот модуль вызван буквой v! Все функции MPI, о которых мы будем говорить, оканчиваются на v - например, MPI_Scatterv. Вы можете представлять себе, что v замещает что-либо, подобное "изменению varying" или "переменной variable". Это связано с тем, что эти функции позволяют Вам изменять как (1) размер, так и (2) местоположение в памяти сообщений, которые Вы используете для коммуникации. В качестве примеров для объяснения основных идей мы возьмем MPI_Scatterv и MPI_Gatherv, но Вы легко можете расширить данные идеи на MPI_Allgatherv и MPI_Alltoallv.
- Преимущества использования v:
- больше гибкости при записи кода
- меньше потребности в копировании данных во временные буфера
- более компактный конечный код
- поставляемая реализация может быть оптимальной
(иначе можно поторговаться с поставщиком по поводу удобства работы)
Как Вы увидите, есть несколько преимуществ для использования этих более общих MPI - вызовов. Основное - в том, что меньше надобности в перестановке данных в пределах процессора перед выполнением коллективной операции MPI. Кроме того, когда Вы используете эти запросы, Вы даете поставщику возможность оптимизировать движение данных для вашей специфической платформы. Но даже если поставщик реализации не потрудился оптимизировать для Вас операцию, подобную MPI_Gatherv, то для Вас всегда будет более удобным и компактным использовать только один вызов MPI_Gatherv, тем более, если ваш образец доступа к данным нерегулярен.
2. Scatter против Scatterv
2.1 Scatter (размещение "один-каждому")
Scatter (размещение "один-каждому") требует непрерывные данные, однородный размер сообщения
- Цель операции размещения "один-каждому" (разброса):
- отправить различные порции данных различным процессам
- не совпадает с широким распространением broadcast (когда тот же самый кусок идет ко всем)
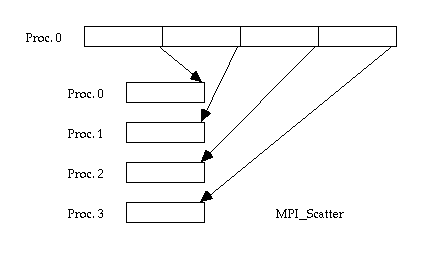
Для нашего первого примера, давайте сравнивать scatter (размещение-разброс) и scatterv. Напомним, что цель функции scatter (размещения) состоит в том, чтобы отослать различные порции данных к различным задачам - то есть, Вы пробуете разбить ваши данные по отдаленным процессам. Напомним также, что scatter (размещение-разброс) - не совпадает с broadcast (широким размещением) - в broadcast ту же самую порцию данных отправляют каждому. Как Вы можете видеть из рисунка, основная функция MPI_Scatter требует, чтобы данные отправителя были сохранены в непрерывных адресах памяти и что куски являются однородными по размеру. Таким образом, первые N элементов данных отправляют первому процессу в коммуникаторе, следующие N элементов идут во второй процесс, и так далее. Однако, для некоторых приложений это может оказаться чрезмерным ограничением. Что, если некоторым процессам надо меньше чем N элементов, например? Должны ли Вы увеличивать буфер отправки ненужными данными? Ответ - нет: Вам следует вместо этого использовать MPI_Scatterv .
2.2 Scatterv (гибкое размещение-разброс "один-каждому")
- Дополнительные возможности в scatterv:
- позволены промежутки между сообщениями в исходных данных
- (но индивидуальные сообщения все еще должны быть непрерывными)
- разрешены нерегулярные размеры сообщения
- данные могут быть распределены по процессам в любом порядке
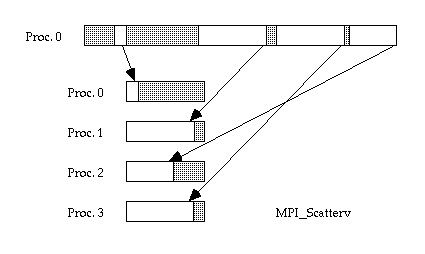
MPI_Scatterv дает Вам дополнительные возможности, которые наиболее легко описать, сравнивая этот рисунок с предыдущим. Прежде всего, Вы можете видеть, что различное число элементов допустимо отправлять различным процессорам. К тому же, первый элемент в каждом куске не должен быть позиционирован по некоторому постоянному промежутку от первого элемента предыдущего куска. И даже нет необходимости сохранять куски в правильной последовательности! Это - гибкость, на которую ранее ссылались. Однако, мы не покончили со всеми ограничениями: сами куски все еще должны быть непрерывными, и они не должны пересекаться друг с другом. (Здесь можно отметить в качестве вводного примечания, что, если Вы действительно хотите, то Вы можете вставить интервалы в кусок, создавая производный тип данных MPI, который имеет некоторый встроенный большой шаг. Но такая уловка может нести потенциально серьезную потерю эффективности, и кускам все еще не позволено пересекаться.)
- int sendcounts[nproc], displs[nproc];
- ...
- MPI_Scatterv
- ( sendbuf, sendcounts, displs, sendtype,
- recvbuf, recvcount, recvtype,
- root, comm);
Является ли действительно синтаксис осуществления операции MPI_Scatterv довольно прямым, или, скажем даже, самообъясняющим? Так или иначе, здесь представлено, как он выглядит на С. По сравнению с простым разбросом Scatter, есть два различия: аргумент sendcounts стал массивом, и, кроме того, в список аргументов был добавлен новый аргумент: displs .
- sendcounts[i] является числом элементов типа sendtype,
- которые следует отправить с процесса root процессу i.
Таким образом его значение существенно только на root.- displs[i] является смещением от sendbuf к
- началу i-го сообщения, в единицах sendtype.
Это также имеет значение только для процесса root.
И это в значительной степени всё, что нам надо! Другие параметры в списке просто отражают обычную последовательность вызовов MPI_Scatter.
- int recvcounts[nproc], displs[nproc];
- ...
- MPI_Gatherv
- ( sendbuf, sendcount, sendtype,
- recvbuf, recvcounts, displs, recvtype,
- root, comm, ierror )
5. Когда эти вызовы могут пригодиться?
5.1 Пример проблемы
Пример: Процесс 0 считывает исходные данные и распределяет их по
другим процессам, в соответствии с декомпозицией домена.
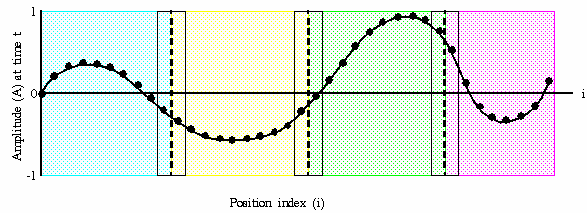
Проблема:Что, если число точек не может быть разделено равномерно?
Типичное использование MPI_Scatterv может возникнуть, когда Вы распределяете начальные данные в код с параллельными данными. Другими словами, предполагается, что Вы параллелизуете ваш код через декомпозицию домена. Очевидно, если число точек не является делимым на число процессов, то не все процессы получат то же самое число точек данных. На этой упрощенной иллюстрации процесс 0 изначально имеет все данные, в то время как цвета указывают возможное целевое распределение точек данных по процессам, включая процесс 0.
nmin=npts/nprocs; nextra=npts%nprocs; k=0; for(i=0;i< nprocs-1;i++) {
- if(i< nextra) sendcounts[i]=nmin+1;
- else sendcount[i]=nmin;
- displa[i]=k;
- k=k+sendcounts[i];
} MPI_Scatterv(sendbuf,sendcounts,displa ...);
Здесь код делит точки среди процессоров настолько равномерно, насколько это возможно. Вначале, используя функцию модуля, выясняется, сколько есть дополнительных точек. Затем осуществляется цикл по процессам. Через массив sendcounts добавляется по одной дополнительной точке на каждый процесс, пока все дополнительные точки nextra не будут учтены. И в то время, как все это происходит, используется массив displs, чтобы следить за относительными стартовыми местоположениями кусков. Наконец, MPI_Scatterv вызывается с расчетными массивами sendcounts и displs, чтобы выполнить желаемое распределение данных.
Домашняя страница MPI в Argonne National Labs http://www.mcs.anl.gov/mpi
Литература
![[Example]](../gifs/example.gif) Выборка примеров программ, которые доступны в Интернете и иллюстрируют команды,
охваченные в этом модуле.
Выборка примеров программ, которые доступны в Интернете и иллюстрируют команды,
охваченные в этом модуле.
|
© 2003
Вычислительный центр им. А.А.Дородницына
Все права защищены. |
|
