Вычислительный центр им. А.А. Дородницына РАНРаздел виртуального курса
|
|
|---|

Вычислительный центр им. А.А. Дородницына РАНРаздел виртуального курса
|
|
|---|
Литература
 Лабораторная работа
Вопросы
Лабораторная работа
Вопросы
Попарная коммуникация (от точки к точке) включает передачу сообщения между одной парой процессов, что противостоит коллективной коммуникации, включающей группу задач. MPI отличается широким кругом попарных коммуникаций чем большинство других библиотек передачи сообщений.
во многих библиотеках предачи сообщений, таких как PVM или MPI, метод, по которому система обрабатывает сообщения выбран разработчиком библиотеки. Выбранный метод дает приемлемую надежность и эффективность работы для всех возможных сценариев коммуникации. Но это может скрыть возможные проблемы программирования либо может не дать наилучшую из возможных эффективность в точно определенных условиях. Для MPI это эквивалентно стандарному способу коммуникации, который будет приведен в этом модуле.
В MPI большая часть контроля того, как система управляет сообщением, отдано программистам, которые выбирают способ коммуникации в момент выбора функции отправки. В дополнение к стандартному способу, MPI обеспечивает синхронный, по готовности и буферный способы. В данном разделе курса (модуле) посмотрим на поведение системы для каждого способа и обсудим их преимущества и недостатки.
В дополнение к выбору способа коммуникации программист должен решить будут ли вызовы отправки и получения блокирующими или неблокирующими. Блокирующая или неблокирующая отправка может быть спарена с блокирующим или неблокирующим получением.
Блокирующий подвешивает исполнение, до тех пор пока буфер сообщения безопасно используется. В обоих способах отправления и получения буфер, используемый для содержания сообщения может оказаться не используемым ресурсом и данные могут быть искажены, когда он используется до того как проходящий перевод завершен; блокирующие коммуникации гарантируют что этого никогда не случится -- когда контроль возвращается от блокирующего вызова, буфер может быть безопасно модифицирован без какой-либо опасности запортить некоторую часть процесса.
Неблокирующий отделяет коммуникацию от вычисления.
Неблокирующий может эффективно гарантировать, что прерывание будет сгенерировано
когда сообщение (перевод, транзакция) готово к выполнению, тем самым позволяя
оригинальной нити вернуться назад к вычислительно-ориентированной обработке.
2. Блокирующее поведение
Прежде чем приступить к изложению способов коммуникации давайте повторим синтаксис блокирующих отправки и получения:
MPI_Send является блокирующей отправкой (передача сообщения с блокировкой). Это означает, что вызов не возвращает управление к вашей программе до тех пор пока данные не будут скопированы в место, определенное вами в листе параметров. Из-за этого, вы можете изменить данные после вызова, не воздействуя на оригинальное сообщение. (Существуют неблокирующие отправки, в которых это не имеет места.)
buf начало буфера, содержащего
данные для отправки. Для C это -- адрес.
count число элементов для отправки (не байт)
datatype тип данных
dest ранг процесса, который является назначением сообщения
tag произвольное число, которое можно использовать для отличия данного сообщения от других
comm это -- коммуникатор
Подобно MPI_Send, MPI_Recv является блокирующей. Это означает, что вызов не возвращает управление в вашу программу, до тех пор пока все получаемые данные не будут запомнены в переменных, которые вы определили в листе параметров. Из-за этого, вы можете использовать данные после вызова и быть уверены что все они здесь. (Существуют неблокирующие получения, в которых это не имеет места.)
buf начало буфера для хранения приходящих
данных. Для C это -- адрес.
count число элементов (не байт) в вашем буфере получения
datatype тип данных
source это -- источник, то есть
ранг процесса из которого данные будут приняты
(Источник отправления может быть назначен любым (джокером -- wildcard),
если определить параметр MPI_ANY_SOURCE.)
tag это -- тег, то есть произвольное число,
которое можно использовать для отличия
данного сообщения от других.
(Тег принимаемого сообщения может быть любым (джокером -- wildcard),
если определить параметр MPI_ANY_TAG.)
comm это -- коммуникатор
status это -- статус, который является массивом
или структурой возвращаемой информации.
Например, если вы определяете источник или тег любым,
status покажет вам действительный ранг или тег для полученного сообщения.
Способ коммуникации выбирается функцией отправки. Существуют четыре функции блокирующей отправки и четыре функции неблокирующей отправки, соответствующие четырем способам коммуникации. Функция получения не определяет способ коммуникации -- она является просто блокирующей или неблокирующей.
Нижеследующая таблица суммирует вызовы отправки и получения, которые будут описаны в данном модуле.
| Способ коммуникации | Блокирующие функции | Неблокирующие функции |
|---|---|---|
| Синхронный | MPI_Ssend | MPI_Issend |
| По готовности | MPI_Rsend | MPI_Irsend |
| Буферизованный | MPI_Bsend | MPI_Ibsend |
| Стандартный | MPI_Send | MPI_Isend |
| MPI_Recv | MPI_Irecv | |
| MPI_Sendrecv | ||
| MPI_Sendrecv_replace |
Начнем изучение поведения блокирующей коммуникации для четырех
способов, начав с синхронного способа. Для компактности изложения придержим изучение
неблокирующего поведения до следующего раздела.
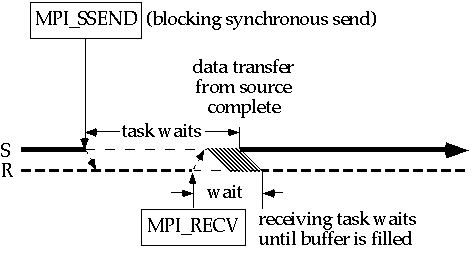
2.1.1 Блокирующая синхронная отправка
На диаграмме, приведенной ниже, время течет слева направо. Жирная горизонтальная линия, помеченная S представляет время исполнения для задачи отправки (на одном узле ), а жирная пунктирная линия, помеченная R, представляет время исполнения для задачи получения (на втором узле). Разрывы в этих линиях представляют прерывания, обусловленные событием передачи сообщения.
![[Try This]](../gifs/try1.gif) Флэш-анимация
Флэш-анимация
Когда блокирующая синхронная отправка MPI_Ssend исполняется, задача отправки отправляет задаче получения сообщение "готова к отправке". Когда задача получателя исполняет вызов получения, она посылает сообщение "готова к получению". Затем данные передаются.
Существуют два источника накладок (overhead) в передаче сообщений. Системная накладка вызывается копированием данных сообщения из буфера сообщения отправителя и копированием данных из сети в буфер сообщения получателя.
Синхронизационная накладка есть время, потраченное на событие ожидании другой задачи. На вышеприведенном рисунке, отправитель должен ждать для исполнения события получения и для наступления встречи перед тем как сообщение может быть передано. Получатель также подвержен некоторой синхронизационной накладке при ожидании завершения встречи. Неудивительно, что синхронизационная накладка может быть значительной в синхронном способе. Как мы увидим, другие способы используют разные стратегии для сокращения этой накладки.
Только один относительный выбор времени для вызовов ( MPI_Ssend и MPI_Recv показан, но они могут прийти в любом порядке. Если вызов получения предшествует отправке, большую часть синхронизационной накладки будет нести получатель.
Кто-то может надеяться, что если работа соответствующим образом сбалансирована по загрузке, синхронизационная накладка будет минимальна для обеих задач: и отправления, и получения. Это не всегда реально. Если ничего больше не вызывает отсутствия синхронизации, то системные службы, которые выполняются в непредсказуемое время на различных узлах, вызовут несинхронизированные задержки. Кто-то может ответить на это сказав, что будет проще просто часто вызывать MPI_Barrier, чтобы сохранить задачи синхронными, но это вызов сам по себе испытывает синхронизационную накладку и не гарантирует, что задачи будут синхронными несколькими секундами позже. Таким образом, вызов барьера почти всегда является потерей времени. (MPI_Barrier блокирует вызовы, пока все члены группы не вызовут его.)
Флэш-анимация
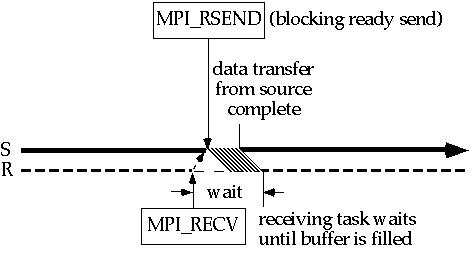
Отправка способом по готовности MPI_Rsend просто отсылает сообщение вовне над сетью. Она требует, чтобы прибыло уведомление "готова к получению", указывая, что задача получения послана на получение. Если сообщение "готова к получению" не прибыло, то отправка способом по готовности выдаст ошибку. По умолчанию, код будет существовать. Программист может связать различное управление по ошибке с коммуникатором, чтобы избежать это поведение по умолчанию. Диаграмма показывает последнюю посылку MPI_Recv , которая не вызвала бы ошибку.
Способ по готовности имеет целью минимизировать системную накладку и синхронизационную накладку вызванную звдачей отправления. В блокирующем случае, единственным ожиданием на отправляющем узле является ожидание того момента, пока все данные не будут премещены вовне из буфера сообщения задачи. Получение может все еще нести существенную синхронизационную накладку, зависящую от того насколько ранее оно исполняется, чем соответствующая отправка.
Этот способ не следует использовать кроме случая, когда пользователь уверен, что сооветствующее уведомление о готовности получения послано.
Флэш-анимация
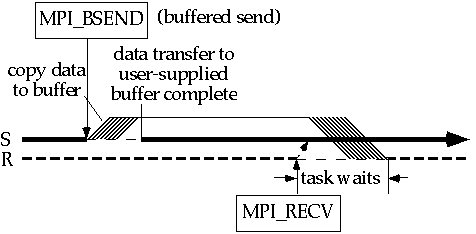
Блокирующая буферизованная отправка MPI_Bsend (S) копирует данные из буфера сообщения в буфер предложенный пользователем и затем возвращает. Отправляющая задача может поэтому выполнять вычисления, которые модифицируют оригинальный буфер сообщения зная что эти модификации не будут отражены в данных, действительно отправленных. Данные будут скопированы из предложенного пользователем буфера на сеть, когда будет получено уведомление "готова получить".
Буферизованный способ испытывает дополнительную системную накладку из-за дополнительного копирования буфера сообщения в предложенный пользователем буфер. Синхронизационная накладка исключается на задаче отправки -- время получения теперь не имеет отношение к отправителю. Всякий раз как получение исполняется до отправки, оно должно ожидать прибытия сообщения до того, как оно может вернуться.
Другой выгодой для пользователя является возможность обеспечить то количество буферного пространства для исходящих сообщений, в котором программа нуждается. С обратной стороны, пользователь ответственен за управление и прикрепление этого буферного пространства. Буферизованный способ отправки, который требует больше буферного пространства чем имеется в наличии, сгенерирует ошибку, и (по-умолчанию) программа завершит работу.
Для буферизованного способа отправки пользователь должен обеспечить буфер: он может быть статически распределенным массивом или память для буфера может быть динамически распределена функцией malloc. Количество памяти, распределенное для предложенного пользователем буфера должно превышать сумму данных сообщения, ибо заголовки сообщения должны также быть запомнены.
Это пространство должно быть идентифицировано, как предложенный пользователем буфер, посредством вызова MPI_Buffer_attach . Когда в этом больше нет нужды, это отделяют MPI_Buffer_detach. В каждый момент времени может быть активным только один предложеный пользователем буфер сообщения. Он запомнит многочисленные сообщения. Система сохраняет след, когда сообщения в конце концов покидают буфер и переиспользует буферное пространство. Безопасность программы не должна зависеть от этого обстоятельства.
Для стандартного способа библиотечный исполнитель определяет системное поведение, которое будет работать наилучшим образом для большинства пользователей на заданной системе. (См для MPICH).
Поведение, когда размер сообщения меньше или равен порогу показан ниже:
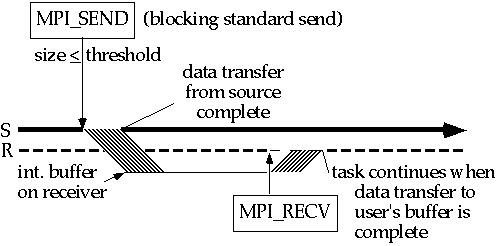
Флэш анимация
В этом случае блокирующая стандартная отправка MPI_Send копирует сообщение на сети в системный буфер на узле получателя. Стандартная отправка затем возвращается и отправляющая задача может продолжать вычисление. Системный буфер прикрепляется, когда программа стартует -- пользователю нет нужды управлять этим каким-либо способом. Существует один системный буфер на задачу, который будет содержать множественные сообщения. Сообщение будет скопировано из системного буфера в задачу получения, когда вызов получения исполняется.
Как и в буферизованном способе использование буфера уменьшает вероятность синхронизационной накладки на отправляющей задаче за счет увеличения системной накладки, получающейся из дополнительного копирования в этот буфер. Как всегда, синхронизационная накладка может быть навлечена получающей задачей, если получение послано первым.
В отличие от буферизованного способа задача отправки не влечет за собой ошибки, если буферное пространство превышается. Вместо этого задача отправки заблокируется до тех пор пока задача получения вызовет получение, которое выгрузит данные из системного буфера. Таким образом, отправляющая задача все еще может влезть в синхронизационную накладку.
Когда размер сообщения больше, чем порог, поведение блокирующей стандартной отпраки MPI_Send по-существу тоже самое как для синхронного способа.
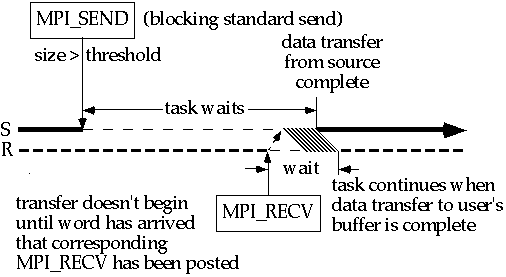
Почему поведение стандартного способа отличается по размеру сообщения? Маленькие сообщения выигрывают от уменьшающегося шанса синхронизационной накладки, получающейся от использования системного буфера. Тем не менее, по мере увеличения размера сообщения стоимость копирования в буфер возрастает и, в конце концов, становится невозможным обеспечить достаточное пространство системного буфера. Таким образом, стандартный способ пытается обеспечить наилучший компромис.
Вы теперь увидели поведение системы для всех четырех способов коммуникации для блокирующих отправлений.
Синхронизированный способ является "безопаснейшим", и потому также наиболее переносимым. "Безопасность" означает, что если код выполняют при одном и том же наборе условий (то есть, размерах сообщений, или архитектуре), то он выполнится при всех условиях. Синхронный код безопасен, так как он не зависит от порядка, в котором отправка и получение исполняются (в отличие от способа по готовности) или количества буферного пространства (в отличие от буферизованного способа или стандартного способа). Синхронизационный способ может вызвать существенную синхронизационную накладку.
Способ по готовности имеет наименьшую суммарную накладку. Он действительно не требует встречи (рукопожатия) отправителя и получателя (подобно синхронизированному способу) или дополнительного копирования в буфер (подобно буферизованному или стандартному способу). Тем не менее, получение должно предшествовать отправке. Этот способ не подходит для всех сообщений.
Буферизованный способ разъединяет отправителя и получателя. Это исключает синхронизационную накладку на отправляющей задаче и гарантирует, что порядок исполнения отправки и получения не имеет значения (в отличие от способа по готовности). Дополнительным преимуществом является то, что программист может контролировать размер сообщений, которые будут буферизованы и полное количество буферного пространства. Существует дополнительная системная накладка, вызванная копированием в буфер.
Поведение стандартного способа определяется реализацией. Разработчик библиотеки
выбирает системное поведение, что обеспечивает хорошую эффективность работы и приемлемую безопасность.
3. Неблокирующее поведение
Блокирующие вызовы отправки и получения подвешивают (приостанавливают) исполнение программы до момента, когда буфер сообщения безопасно использовать для отправления/получения. В случае блокирующей отправки это означает, что данные, которые будут отправлены должны быть скопированы из буфера отправки, но они не обязаны быть получены получающей задачей. Содержимое буфера отправки может быть модифицировано без воздействия на отправленное сообщение. Завершение блокирующего получения подразумевает, что данные в буфере получения правильные.
Неблокирующие вызовы возвращаются немедленно после инициации коммуникации. Программист не знает в этой точке являются ли данные, которые надо отправить, скопированы из буфера отправки, или являются ли данные, которые надо получить, прибывшими. Таким образом, перед использованием буфера сообщения программист должен проверить его статус. Описание статуса будет охвачено в следующем модуле MPI попарный обмен сообщениями II.
Программист может выбрать блокировку пока буфер сообщения безопасно использовать, посредством вызова MPI_Wait и его вариантов или только возвращая текущий статус коммуникации посредством MPI_Test и его вариантов .
Различные варианты вызовов Wait и Test позволяют вам проверить статус точно определенного сообщения или проверить все, любой, или некоторые из списка сообщений.
Интуитивно ясно почему вам надо проверить статус неблокирующего получения: вам дествительно не хочется считывать сообщение пока вы не убедились, что это сообщение прибыло. Менее очевидно, почему вам нужно проверить статус неблокирующего отправления. Это чрезвычайно необходимо когда вы имеете цикл, который повторно заполняет буфер сообщения и отправляет сообщение. Вы не можете записать что-нибудь новое в буфер пока вы не уверитесь наверняка, что предыдущее сообщение успешно скопировано из буфера. Если даже буфер отправки не используется повторно, выгодно завершить коммуникацию, так как это освобождает системные ресурсы.
3.1 Синтаксис неблокирующих вызовов
Неблокирующие вызовы имеют тот же синтаксис
как и блокирующие с двумя исключениями:
Аналогично, неблокирующий вызов получения есть MPI_Irecv.
Вызовы Wait и Test берут один или несколько способов доступа к запросу как вход и возвращают один или более статусов. В дополнение, Test указывает завершилась ли любая из коммуникаций, к которым запрос обращается. Wait, Test, и статус обсуждаются в деталях в модуле о попарном обмене сообщениями II.
3.2 Пример: Неблокирующая стандартная отправка
Мы посмотрели блокирующее поведение для каждого споосба коммуникации. Теперь обсудим неблокирующее поведение для стандартного способа. Поведение других способов может быть выведено отсюда.
Следующий рисунок показывает использование обоих вызовов: неблокирующей стандартной отправки MPI_Isend и неблокирующего получения MPI_Irecv . Как и раньше, отправка стандартным способом выполнится по-разному в зависимости от размера сообщения. Следующий рисунок демонстрирует это поведение для размера сообщения, который не превышает порога.
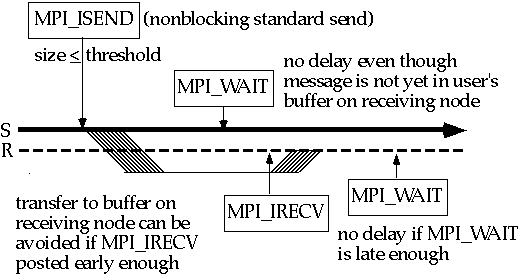
Отправляющая задача посылает неблокирующую стандартную отправку, когда содержимое буфера сообщения готово к тому. чтобы быть перемещено. Ее возврат происходит немедленно без ожидания завершения копирования в удаленный системный буфер. MPI_Wait вызывается как раз перед тем, как отправляющая задача нуждается в перезаписи буфера сообщения.
Получающая задача вызывает неблокирующее получение как только буфер сообщения будет пригоден вместить сообщение. Возврат из неблокирующего получения происходит без ожидания прибытия сообщения. Задача получения вызывает MPI_Wait, когда ей нужно использовать данные входящего сообщения (то есть, когда есть необходимость быть уверенным, что они прибыли).
Системная накладка не отличается существенно от накладки при блокирующих вызовах отправки и получения за исключением того, что перевод данных и вычисления могут происходить одновременно. Так как ЦПУ может понадобиться, чтобы выполнить как передачу данных, так и вычисления, вычисления будут прерваны на обоих отправляющем и получающем узлах чтобы переправить сообщение. Момент времени, когда прерывание случается не должно как-то особо влиять на выполняемую программу. Даже для архитектур, которые перекрывают вычисления и коммуникацию, факт, что этот случай применяется только к малым сообщениям, означает, что не стоит ожидать большой разницы в эффективности работы.
Преимущество в использовании неблокирующей отправки происходит, когда отдаленный системный буфер полон. В этом случае блокирующая отправка была бы должна ожидать пока принимающая задача выгрузит некоторые данные сообщения из буфера. Если используется неблокирующий вызов, то вычисление может быть сделано во время этого интервала.
Преимущество неблокирующего получения перед блокирующим может быть значительным, если получение послано перед отправкой. Задача может продолжать вычисления пока не посылается Wait, что лучше, чем сидеть впустую. Это уменьшает итог синхронизационной накладки.
Неблокирующие вызовы могут гарантировать, что не получится, что оба процессора ожидают друг друга. Этот Wait должен быть послан после того, как вызовы понадобятся, чтобы завершить коммуникацию.
3.3 Пример: Неблокирующая стандартная отправка, большое сообщение
Случай неблокирующей стандартной отправки MPI_Isend для сообщения, которое превышает порог, более интересно:
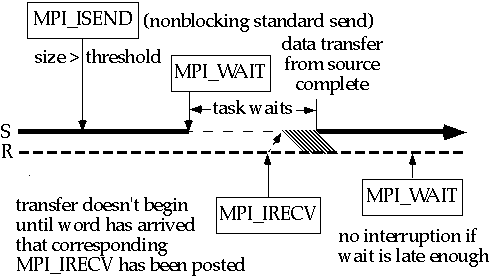
Для блокирующей отправки синхронизационной накладкой будет период между блокирующим вызовом и копированием в сеть. Для неблокирующего вызова синхронизационная накладка сокращается на количество времени между неблокирующим вызовом и MPI_Wait, во время которого полезные вычисления выполняются.
И опять, неблокирующее получение MPI_Irecv сократит синхронизационную накладку на принимающей задаче для случая, в котором получение послано первым. Существует также выгода в использовании неблокирующего получения, когда отправка послана первой. Рассмотрим как рисунок изменится, если бы блокирующее получение было послано. В типичной ситуации блокирующие получения посылаются непосредственно перед тем, как данные сообщения должны быть использованы (чтобы дать максимальное время для завершения коммуникации). Таким образом, блокирующее получение было бы послано на место MPI_Wait. Это задержало бы синхронизацию с вызовом отправки до этой более поздней точки в программе и таким образом увеличило бы синхронизационную накладку на отправляющей задаче.
Получив некоторый опыт с основами MPI, проконсультируйтесь со стандартом или имеющимися учебниками для получения информации по постоянным запросам. Блокирующий вызов передает его с намного меньшими системными издержками чем делает неблокирующий вызов, если вы можете представить, что оба собираются быть удовлетворены немедленно, но если передача не является немедленно удовлетворяемой, то неблокирующий вызов выигрывает до той степени, что "полезные вычисления" могут быть завершены прежде их окончания.
В общем случае, разумно начинать программирование с неблокирующих вызовов и стандартного способа. Неблокирующие вызовы могут исключить возможность тупика и сократить синхронизационную накладку. Стандартный способ дает обычно хорошую эффективность работы.
Блокирующие вызовы могут потребоваться, если программист хочет синхронизовать задачи. Также, если программа требует, чтобы за неблокирующим вызовом немедленно следовал Wait, то намного эффективнее использовать блокирующий вызов. Если используются блокирующие вызовы, то может быть выгодным начать в синхронном способе, и затем переключиться на стандартный способ. Тестирование в синхронном способе гарантирует, что программа не зависит от присутствия достаточного системного буферного пространства.
Следующим шагом является анализ кода и оценка его эффективности работы. Если неблокирующие получения посланы рано, значительно ранее соответствующих отправок, будет выгодно использовать способ по готовности. В этом случае получающая задача должна возможно извещать отправителя после того, как получения посланы. После получения уведомления, отправитель может выполнить отправки.
Если существует слишком большая синхронизационная накладка на отправляющей задаче, особенно для больших писем, буферизованный способ может оказаться более эффективным.
Cornell Theory Center MPI Point to Point Communication I
Богач╦в К.Ю. Основы параллельного программирования. -- М.: БИНОМ. Лаборатория знаний, 2003. -- 342 с.
Немнюгин С.А., Стесик О.Л. Параллельное программирование для многопроцессорных вычислительных систем. -- СПб.: БХВ-Петербург, 2002. -- 400 с.: ил.
MPI Home Page at Argonne National Labs http://www.mcs.anl.gov/mpi
Message Passing Interface Forum (1995) MPI: A Message Passing Interface Standard. June 12, 1995. Доступен на русском языке в pdf-формате из сайта http://www.cluster.bsu.by/MPI_ALL.htm
![[Quiz]](../gifs/quiz.gif) Вопросы для проверки усвоения материала
Вопросы для проверки усвоения материала
![[Exercise]](../gifs/exercise.gif) Лабораторная работа
Лабораторная работа
|
© 2005
Вычислительный центр им. А.А.Дородницына
Все права защищены. |
|