Вычислительный центр им. А.А. Дородницына РАН
Раздел виртуального курса
Параллельное программирование в интерфейсе MPI
|
|
MPI попарный обмен сообщениями II
Содержание
- Обзор
- Основной тупик
- Определение информации о сообщении
- Специальные параметры
- Реализация MPICH
- Рекомендации по программированию
Литература
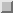
1. Обзор
Начнем с обзора альтернатив программирования, представленных в этом модуле:
Тупик
Ситуация тупика (дэдлока) часто встречается в параллельной
обработке, когда два процесса или больше соревнуются за
один и тот же набор ресурсов.
В типичном сценарии в коммуникацию вовлечены два процесса,
желающих обменяться сообщениями,
причем оба пытаются отдать их противоположному,
хотя ни один еще не готов принять сообщение.
Здесь описан ряд стратегий, помогающих избежать такого рода проблемы,
встречающиеся в приложениях.
Проверка и исполнение по "состоянию" коммуникаций
При вовлечении в неблокирующие транзакции (пересылки) вызов функций
wait (подождать), test (проверить) и probe (прозондировать)
дают приложению возможность запросить статус (status) отдельных сообщений
или проверить любое сообщение, обладающее определенным набором характеристик,
без извлечения любой завершенной транзакции из очереди.
Проверка информации (статуса), возвращаемой из транзакции, позволяет
приложению произвести, например, корректирующие действия,
когда случилась ошибка.
Использование специальных параметров для специальных случаев
Джокеры - MPI_ANY_SOURCE и MPI_ANY_TAG
Использование вызовов с джокерами позволяет получающему процессу
конкретизировать получаемое соообщение,
используя джокер для указания либо отправителя, либо типа сообщения.
Пустые Процессы и Запросы
Специальные пустые параметры могут упростить кодирование
приложений, делая структуры данных регулярными.
2. Основной тупик
Явление тупика (дэдлока) наиболее распространено при
блокирующих коммуникациях. Тупик случается, когда все задачи ожидают событий,
которые еще не были инициализированы.
На следующей диаграмме представлены две задачи типа SPMD
(единственная программа -- множество данных): обе вызывают
блокирующие стандартные отправки в той же точке программы.
Спаренное с отправкой получение у каждой задачи происходит позже
в другой программе этой задачи.
Простейший пример тупика: каждая отправка из двух
ждёт соответствующего ей получения, чтобы завершиться,
но эти получения исполняются после отправок, так
что, если отправки не завершены и не вернулись, то получения никогда не
смогут исполниться и оба набора коммуникаций подвиснут на неопределённое время.
Более сложный пример тупика может произойти, если размер сообщения
больше порога; тупик произойдет из-за того, что ни одна задача не может
согласоваться во времени (синхронизироваться) с соответствующим ей получением.
Тупик все же может произойти и в случае, когда размер сообщения не превышает порога,
если нет достаточного места в системном буфере.
Обе задачи будут ожидать получения, чтобы переписать данные сообщения из
системного буфера, но эти получения не могут исполниться, так как обе задачи
заблокированы в отправке.
Решения для исключения тупиков:
Есть четыре способа избежать тупика:
различный порядок вызовов у задач
Организуйте порядок, в котором одна задача объявляет первой свое получение, а вторая
объявляет первой свою отправку. Это прояснение даст порядок, в котором сообщение
в одном из направлений проходит раньше, чем в другом.
неблокирующие вызовы
заставляют каждую задачу объявить неблокирующее получение до того, как она
произведет какую-нибудь другую коммуникацию.
Это дает возможность получить каждое сообщение независимо от того,
над чем задача трудится, когда сообщение прибывает,
и независимо от порядка, в котором отправки объявлены.
-
Использование MPI_Sendrecv
-- это элегантное решение, использующее возможности
самой библиотеки MPI для исключения тупика. В этой версии используется два буфера:
один для отправляемого сообщения, а другой для получаемого.
В версии _replace система выделяет некоторое
единственное буферное пространство (не зависящее от порогового предела)
для обработки обмена сообщениями.
Отправленное сообщение в этом буфере замещается полученным.
Заметим здесь, что обмен с процессом, который имеет пустое значение
MPI_PROC_NULL, не дает результата, а отправка на пустой процесс
MPI_PROC_NULL всегда успешна.
буферизованный способ
Используйте буферизованную отправку, чтобы можно было осуществлять вычисления
после копирования отправляемого сообщения в пользовательский буфер.
Это дает возможность исполнения получений.
Буферизованные отправки обсуждались ранее
в модуле Попарный обмен сообщениями I.
3. Определение информации о сообщении
В приложениях можно использовать специальные вызовы для контроля
положения дел у незавершенных транзакций или транзакций,
состояние которых неизвестно, без необходимости завершения этих операций
(это аналогично ожиданию информации о том, пришло ли тётино письмо,
не заботясь о его содержании).
Приложение можно запрограммировать так, чтобы знать состояние его коммуникаций,
и поэтому продуманно действовать в различных ситуациях:
3.1 Wait, Test и Probe
Имея успешно расцепленные коммуникации по вашей основной
вычислительной нити, вам, тем не менее, нужно быть способным как к получению
информации о статусе коммуникационной транзакции, так и к систематизации,
чтобы осуществить определенные действия, относящиеся к найденным вами условиям.
Три вызова, описанные здесь, принадлежат к тем, что обычно наиболее полезны
для разрешения этих типов ситуаций.
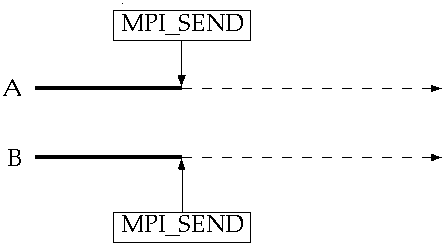
MPI_Wait
Полезен для обоих участников неблокирующей коммуникации:
отправителя и получателя.
Блокирующие коммуникации включают автоматический вызов wait,
поэтому вы никогда не увидите нетривиальный вызов его, когда такие
операции используются. В обоих случаях: и в случае отправки, и в случае получения,
-- для неблокирующих операций, вызывающий процесс откладывает его
функционирование, пока работа, заданная ссылкой wait, завершится,
в этот момент времени исполнение возобновится в вызывающем процессе.
Под управлением программиста получающий процесс заблокирован,
пока сообщение принимается
На стороне получателя процесс уже объявил неблокирующее получение,
которое будет завершено независимо от того, что вызывающий процесс делает.
Программист поэтому способен определить совершено или нет какое-либо полезное
вычисление перед тем как запрашивается информация в еще-не-полученном сообщении
... если есть в наличии полезная работа, приложение определенно приобретет
эффективность совершая эту работу пока сообщение все еще в пути.
В некоторой точке, конечно, сообщение понадобится, и wait будет использован.
Отправляющий процесс заблокирован до тех пор пока операция отправки
завершается, к этому времени буфер сообщения способен к новому
использованию
На стороне отправки процесс также освобождается от
транзакции, за исключением того факта, что он принужден
не записывать что-либо в этот особый буфер до тех пор, пока
его текущее использование не завершится
... если отправитель пытается положить некоторое другое сообщение
в этот буфер до того, как предшествующая пересылка завершится,
результаты не будут определены и будут основаны исключительно на том,
какая часть процесса была в обработке, когда произошла перезапись.
Осуществление wait на сообщение гарантирует, что повторное использование
буфера не будет деструктивным.
-
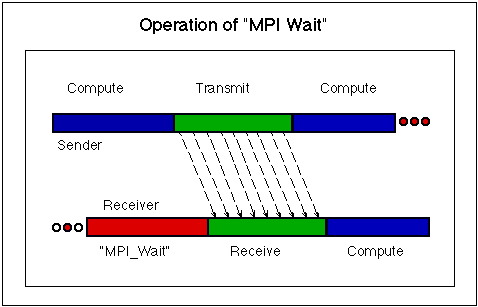
MPI_Test
Используется обоими участниками неблокирующей коммуникации:
отправителем и получателем.
Там где wait задерживает исполнение до тех пор пока операция завершится,
test возвращается немедленно с информацией о ее текущем сосотоянии.
Получатель проверяет, чтобы удостовериться, что определённый
отправитель отослал сообщение, которое ожидает свою передачу
... сообщения от всех других отправителей игнорируются.
Вызов test возратит значение true, только в
случае, который отправитель задал в объекте, что отослан,
некое сообщение, которое теперь находится в очереди на передачу,
поток от всех прочих источников игнорируется.
Отправитель может выяснить может ли буфер-сообщения
быть заново использован
... должен ждать пока операция завершится
до того как делать это.
На стороне отправителя test является неблокирующим аналогом
wait, предоставляя приложению знание текущего состояния
без требования его блокировки до завершения, что позволяет приложению
делать другую работу, если какая-нибудь есть.
- MPI_Probe
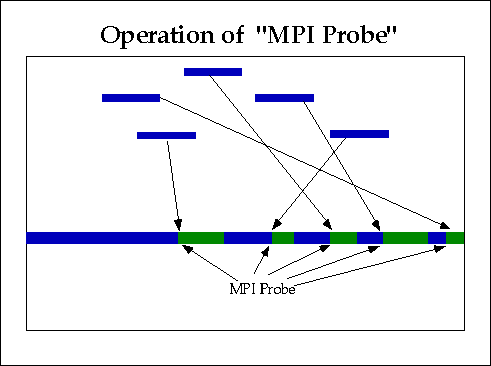
Получатель извещается когда (т.е., это некий блокирующий
вызов) сообщения от потенциально любого отправителя прибывают
и готовы быть выполнены.
Все предыдущие вызовы наметили конкретные сообщения и отправителей;
вызов probe может быть предназначен к возврату "распределяемой"
информации, касающейся как любого отправителя, так и конкретного.
статус возвращает источник, тег и
ошибку (в стандартном случае)
Статус - это объект, на который смотрят,
чтобы определить информацию об источнике и теге сообщения и любой ошибке,
которой может быть подвергнут коммуникационный вызов.
В C они возвращаются как status.MPI_SOURCE, status.MPI_TAG и
status.MPI_ERROR. В случае отправок, информация о статусе
скорее всего не отличается от той, что была в вызове, так что ее
редко используют.
MPI_Get_count возвращает
число элементов
Это может быть полезно, если вы распределили буфер получателя,
который может быть больше, чем входящее сообщение, или если вы
хотите узнать длину сообщения, идентифицированного
MPI_Probe.
Условия, в которых имеет смысл проверять статус
Эта информация, которую представляет статус,
становится очень удобной, когда имеют дело со следующей
ситуацией, предлагаемой без обсуждения, как
изменяющиеся подробности,
уже охваченные где бы то ни было (за исключением
MPI_ANY_TAG и
MPI_ANY_SOURCE,
которые будут кратко охвачены):
блокирующее получение или ожидание,
когда MPI_ANY_TAG или
MPI_ANY_SOURCE
должны быть использованы
MPI_ANY_TAG,
принимает сообщение с любым значение тега
MPI_ANY_SOURCE, принимает сообщение
от любого источника
MPI_Probe
или MPI_Iprobe
для получения информации по приходящим
сообщениям
MPI_Probe - блокирующий тест для
некоторого сообщения
MPI_Iprobe - неблокирующий тест для
некоторого сообщения
MPI_Test
служит для того, чтобы узнать завершена ли коммуникация
4. Специальные параметры
Джокеры (заменители) - MPI_ANY_SOURCE и MPI_ANY_TAG
Родовой термин, имеющий значение
"что-либо, отвечающее очень общему множеству
характеристик."
MPI_ANY_SOURCE позволяет получателю получить
сообщения от любого отправителя, и
MPI_ANY_TAG позволяет получателю получить
любой тип сообщения от отправителя.
Пустые (фиктивные) процессы и запросы
Приложения часто имеют дело с регулярными структурами данных,
такими как прямоугольные гипер-массивы, и выполняют один и тот же тип
коммуникаций везде внутри их, за исключением краев, для которых приходится
писать специальный код, чтобы не осуществлять коммуникации там,
где нет действительных "соседей" для отправки или получения;
специальные пустые параметры перемещают логику этого
из пользовательского кода в систему, упрощая создание приложения.
5. Реализация MPICH
В реализации MPICH стандартный, синхронный и
буферизованный способы работают так, как предписано
стандартом. (???)
6. Рекомендации по программированию
Избегайте тупика посредством продуманного размещения
вызовов отправок/получений или ранним объявлением неблокирующих получений.
Если вы выбрали использование блокирующих транзакций, пытайтесь
обеспечить исключение тупика посредством тщательной разработки
вашей коммуникационной стратегии, в которой отправки и получения
надлежащим образом спарены в необходимом порядке; в противном случае,
объявите неблокирующие получения настолько рано, насколько это возможно,
так что отправки будут простаивать в системе так мало времени, как это
необходимо.
Используйте уместный вызов "состояния операции" ("wait",
"test" или "probe"), чтобы держать под контролем функционирование
вызовов неблокирующих коммуникаций.
Корректное знание состояния коммуникационных транзакций
позволяет приложению продуманно управляться с работой, улучшая
эффективность использования имеющихся циклов. В конце концов
подвешенный обмен должен быть принят, но такое действие может долго быть в пути
и многие транзакции, возможно, могут быть выполнены, хотя и не завершены.
Вызовы wait, test и probe позволяют приложению соединить
соответствующую деятельность с индивидуальной ситуацией.
Проверь значения полей "статуса (status)" для сообщения проблемы.
Не предполагайте просто, что все пройдет гладко -- сделайте
общим правилом проверку на успех любой транзакции и то, чтобы
фатальные ошибки немедленно сообщались, и так много относящейся к делу
информации, насколько возможно, развивается и делается доступным для
отладки.
Продуманное использование джокеров может
значительно упростить логику и кодирование.
Используя общие параметры, получения способны обработать более чем
один тип потока сообщений (в терминах либо отправителя, либо
типа сообщения, либо обоих), что может значительно упростить структуру
вашего приложения и потенциально может дать экономию на системных ресурсах
(если у вас есть привычка использовать уникальный буфер сообщения для
каждой транзакции).
Пустые (фиктивные) процессы и запросы перемещают тесты вовне пользовательского кода.
Использование MPI_PROC_NULL и MPI_REQUEST_NULL не дает освобождения от
граничных тестов, а просто позволяет программисту использовать вызов,
который будет проигнорирован системой.
Литература
Cornell Theory Center
MPI Point to Point Communication I
Богачёв К.Ю. Основы параллельного программирования. --
М.: БИНОМ. Лаборатория знаний, 2003. -- 342 с.
Немнюгин С.А., Стесик О.Л. Параллельное программирование для многопроцессорных
вычислительных систем. -- СПб.: БХВ-Петербург, 2002. -- 400 с.: ил.
MPI Home Page at Argonne National Labs http://www.mcs.anl.gov/mpi
Message Passing Interface Forum (1995) MPI: A Message Passing
Interface Standard. June 12, 1995. Доступен на русском языке в pdf-формате из сайта http://www.cluster.bsu.by/MPI_ALL.htm
![[Quiz]](../gifs/quiz.gif) Вопросы для проверки усвоения материала
Вопросы для проверки усвоения материала
![[Exercise]](../gifs/exercise.gif) Лабораторная работа
Лабораторная работа
