Вычислительный центр им. А.А. Дородницына РАНРаздел виртуального курса
|
|
|---|
Вычислительный центр им. А.А. Дородницына РАНРаздел виртуального курса
|
|
|---|
 Лабораторная работа
Вопросы
Лабораторная работа
Вопросы
1. Обзор MPI
1.1 Что такое MPI?
MPI - это библиотека передачи сообщений, собрание функций на C/C++ (или подпрограмм в Фортране,
которые, зная MPI для C/C++, легко изучить самостоятельно), облегчающих коммуникацию (обмен данными и
синхронизацию
задач)
между процессами параллельной программы с
распределенной памятью
.
Акроним (сокращение по первым буквам) установлен для
Message Passing Interface (интерфейс передачи сообщений).
MPI является на данный момент фактическим стандартом и
самой развитой переносимой библиотекой параллельного
программирования с передачей сообщений.
MPI не является формальным стандартом, подобным тем, что выпускают организации стандартизации, такие как Госкомстандарт РФ, ANSI или ISO. Вместо этого, он является "стандартом по консенсусу", спроектированном на открытом форуме, который включал крупных поставщиков компьютеров, исследователей, разработчиков библиотек программ и пользователей, представляющих более 40 организаций. Такое широкое участие в его развитии гарантировало быстрое превращение MPI в широко используемый стандарт для написания параллельных программ передачи сообщений.
"Стандарт" MPI был введен MPI - форумом в мае 1994 и обновлен в июне 1995. Документ, который определяет его, озаглавлен "MPI: A Message-Passing Standard", опубликован университетом Тэннеси и доступен по World Wide Web в Argonne National Lab. Если вы еще не знакомы с MPI, то, возможно, вы захотите распечатать перевод этого документа на русский язык и использовать его для получения справок о синтаксисе функций MPI, которые данный курс не может охватить полностью за исключением иллюстрации частных случаев.
MPI 2 производит расширения к стандарту MPI передачи сообщений. Эти усилия не изменили MPI; они расширили применение MPI на следующие сферы:
MPI 2 был завершен в июле 1997.
1.2 Что MPI предлагает?
MPI предлагает переносимость, стандартизацию, эффективную работу,
функциональность и имеет ряд высококачественных реализаций.
MPI стандартизован на многих уровнях. Например, поскольку синтакс стандартен, вы можете положиться на ваш MPI код при запуске в любой реализации MPI, работающей на вашей архитектуре. Поскольку функциональное поведение вызовов MPI довольно стандартизовано, нет нужды беспокоиться о том, какая реализация MPI установлена сейчас на вашей машине; ваши вызовы MPI должны вести себя одинаково независимо от реализации. Эффективность работы, тем не менее, слегка меняется в зависимости от реализации.
В быстро изменяющемся окружении высоко производительных компьютеров и технологий коммуникации, переносимость (мобильность) почти всегда важна. Кто захочет развивать программу, которая может выполняться только на одной машине, или только с дополнительными затратами труда на других машинах? Все системы массивной параллельной обработки обеспечивают своего рода библиотеку передачи сообщений, которая точно определена аппаратными средствами используемой ЭВМ. Они обеспечивают прекрасную эффективность работы, но прикладной код, написанный для одной платформы не может быть легко перенесен на другую.
MPI позволяет вам писать портативные программы, которые все еще используют в своих интересах спецификации аппаратных средств ЭВМ и программного обеспечения, предлагаемого поставщиками. К счастью, эти заботы в основном берут на себя запросы MPI, потому что конструкторы настроили эти вызовы на основные аппаратные средства ЭВМ и окружающую среду программного обеспечения.
Множество внешних инструментов, включая PVM, Express и P4, пытались обеспечить стандартизованное окружение для параллельных вычислений. тем не менее, ни одна из этих попыток не показала такой высокой эффективности работы, как MPI.
MPI имеет намного более одной качественной реализации. Эти реализации обеспечивают асинхронную коммуникацию, эффективное управление буфером сообщения, эффективные группы, и богатые функциональные возможности. MPI включает большой набор коллективных операций коммуникации, виртуальных топологий и различных способов коммуникации, и, кроме того, MPI поддерживает библиотеки и неоднородные сети.
Имеющиеся в настоящее время реализации включают
ВЦ РАН и МСЦ используют MPICH-реализацию MPI, последнюю версию которой можно свободно скачать с сайта Argonne National Lab
1.3 Как использовать MPI
Если у вас уже есть последовательная версия программы и вы собираетесь ее модифицировать
используя MPI, перед распараллеливанием убедитесь, что ваша последовательная версия
безукоризненно отлажена.
После этого добавьте вызовы функций MPI в соответствующие места вашей программы.
Если Вы пишете программу MPI с чистого листа, и написать сначала последовательную программу (без вызовов MPI) не составляет большого труда, сделайте это. Повторим, идентификация и удаление непараллельных ошибок вначале намного облегчит отлаживание параллельной программы. Проектируйте ваш параллельный алгоритм, используя в своих интересах любой параллелизм, свойственный вашему последовательному коду, например, большие массивы которые можно разбить на подзадачи и обрабатывать независимо.
Отлаживая параллельную версию удостоверьтесь сначала, что запуски вашей программы успешны на нескольких узлах. Затем постепенно увеличивайте число узлов, например, от 2 до 4, затем 8, и т.д. Таким путем вы не будете тратить впустую много машинного времени на дополнительные ошибки.
В этом параграфе дано введение к простой программе с MPI. Это нужно, чтобы дать наглядное представление об относящихся к делу вопросах, к которым можно потом вернуться, если у вас возникнут вопросы по таким вещам, как
Программа сама по себе не преставляет собой ничего более, чем широко известную программу
Hello, world, поэтому мы не будем касаться понимания цели алгоритма
-- лучше мы сфокусируемся полностью на механизме осуществления параллельной версии
этой чрезвычайно простой задачи
2.1 Формат функций MPI
Во-первых, рассмотрим форматы фактических вызовов, используемых MPI.
Программа на C должна включать файл "mpi.h". Он содержит определения для констант и функций MPI.
Программы Фортран должны обычно включать 'mpif.h' (для компилятора Compaq 'mpif90.h') Этот файл определения для констант и функций MPI.
исключением к вышеприведенным функциям есть функции времени (MPI_Wtime и MPI_Wtick), которые являются функциями как C, так и Фортрана, и возвращают действительные числа с двойной точностью.
Основная схема программы MPI подчиняется следующим общим шагам:
Покажем эти шесть базовых вызовов функций MPI в следующем коде на языке C. Нажав на название каждой функции MPI можно прочесть детальное описание ее предназначения и синтаксиса.
Резюмируя эту программу можно сказать: это код SPMD, так что копии этой программы выполняются на множестве процессоров. Каждый процесс инициализирует себя в MPI (MPI_Init), определяет число процессов (MPI_Comm_size) и узнает его ранг (MPI_Comm_rank). Затем одни процесс (с рангом 0) посылает сообщения в цикле (MPI_Send), устанавливает целевой аргумент (предназначения) в индекс цикла, чтобы быть уверенным, что в каждый из оставшихся процессов посылается одно сообщение. Оставшиеся процессы получают одно сообщение (MPI_Recv). Затем все процессы печатают сообщение и выходят из MPI (MPI_FInalize).
Здесь нет заботы о том, что не произойдет в этой программе. Нет функций, которые вызывают дополнительные копии программы на выполнение. Для запуска программы на выполнение на суперкомпьютере используют команду mpirun.
В упражнении лабораторной работы, ссылка на которую приведена в конце этого модуля, от вас потребуется расширить эту программу некоторыми дополнительными вызовами функций MPI.
3. Сообщения MPI
Сообщения MPI состоят из двух основных частей:
отправляемые/получаемые данные,
и сопроводительная информация (записи на конверте /оболочке/), которая помогает отправить данные
по определенному маршруту.
Обычно существуют три вызываемых параметра в вызовах передачи сообщений MPI,
которые описывают данные и три других параметра, которые определяют маршрут:
| старт буфера, число, тип данных | цель, тег, коммуникатор |
| ДАННЫЕ | ОБОЛОЧКА |
Каждый параметр в данных и оболочке (конверте) будет обсужден более детально ниже, включая информацию о том, когда эти параметры следует координировать между отправителем и получателем.
3.1 Данные
Буфер в вызовах MPI есть место в компьютерной памяти,
из которого сообщения должны быть посланы или где они накапливаются.
В этом смысле буфер -- это просто память, которую компилятор выделил
для переменной (часто массива) в вашей программе.
Следующие три параметра вызова MPI необходимы, чтобы определить буфер:
Адрес, где данные начинаются. Например, начало массива в вашей программе.
Число элементов (пунктов) данных в сообщении. Заметим, что это элементы, а не байты. Это делается для переносимости кода, ибо нет необходимости беспокоиться о различных представлениях типов данных на различных компьютерах. Реализация матобеспечения MPI определяет число байт автоматически. Число, определенное при получении должно быть больше чем или равно числу, определенному при отправке. Если посылается больше данных, чем имеется в хранилище принимающего буфера, то произойдет ошибка.
Тип данных, которые будут передаваться -- с плавающей точкой, например.
Этот тип данных должен быть тем же самым для вызовов отправки и получения.
Исключением из этого правила является тип данных
MPI_PACKED, который является одним из способов обработки сообщений
со смешанным типом данных (предпочтительным методом является метод
с производными типами данных). Проверка типов не нужна в этом случае.
Типы данных уже определенные для вас называются "основными типами данных"
и перечислены ниже
Типы данных MPI Типы данных C MPI_CHAR signed char MPI_SHORT signed short int MPI_INT signed int MPI_LONG signed long int MPI_UNSIGNED_CHAR unsigned char MPI_UNSIGNED_SHORT unsigned short int MPI_UNSIGNED unsigned int MPI_UNSIGNED_LONG unsigned long int MPI_FLOAT float MPI_DOUBLE double MPI_LONG_DOUBLE long double MPI_BYTE MPI_PACKED
Могут быть также определены дополнительные типы данных, названные производными типами данных. Вы можете определить тип данных для несмежных данных или для последовательности смешанных основных типов данных. Это может сделать программирование легче и часто обеспечивает более быстрое выполнение кода. Производные типы данных находятся вне сферы этого введения, но охвачены в модуле Производные типы данных.
Некоторые производные типы данных:
Напомним, что сообщение состоит из данных и оболочки (конверта) сообщения. Оболочка дает информацию о том как связаны отправления с получениями. Три параметра используются для определения оболочки (конверта) сообщения:
Тег (ярлык, метка) -- произвольное число, которое помогает различать сообщения. Теги, опреляемые отправителем и получателем, должны совпадать, но получатель может определить его как MPI_ANY_TAG, чтобы показать, что любой тег приемлем.
Коммуникатор, определенный при отправке должен равняться коммуникатору, определенному при получении. Коммуникаторы будут обсуждаться более глубоко чуть позже в этом же модуле. Сейчас будет достаточно знать, что коммуникатор определяет коммуникационную "вселенную", и то, что процессы могут принадлежать к более чем одному коммуникатору. В этом модуле мы будем иметь дело только с предопределенным коммуникатором MPI_COMM_WORLD, который включает все процессы приложения.
Чтобы легче понять параметры окружения сообщения, рассмотрим аналогию с агентством выпускающим иски (плат╦жные требования - квитанции) по нескольким потребностям. Посылая иск, агентство должно указать:
Раскроем теперь немного больше понятие коммуникатора. Не будем углубляться во все детали - только в те, что обеспечивают некоторое понимание того, как они используются. Коммуникаторы охвачены более глубоко в модуле Управление группами и коммуникаторами MPI.
Приемлемость сообщения для захвата точно определенным вызовом принятия зависит от его источника, тега и коммуникатора. тег позволяет программе различать типы сообщений. Источник упрощает программирование. Вместо того, чтобы иметь уникальный тег для каждого сообщения, каждый процесс, посылающий ту же самую информацию, может использовать тот же тег. Но зачем нужен коммуникатор?
Предположим вы посылаете сообщения между вашими процессами, и, кроме того, вызываете ряд библиотек, полученных откуда-либо, которые также порождают процессы, выполняемые на различных узлах, взаимодействующих друг с другом с помощью MPI. В этом случае вам хотелось бы быть уверенными, что отправленные вами сообщения придут к вашим процессам и не будут смешаны с сообщениями, отправленными между процессами изнутри библиотечных функций.
В этом примере мы имеем три процесса, взаимодействующих друг с другом. Каждый процесс также вызывает библиотечную функцию и три параллельные части библиотеки взаимодействуют друг с другом. Нам хочется иметь два различных "пространства" сообщений, одни для наших сообщений и один для библиотечных сообщений. Нам бы не хотелось получить какое-либо перемешивание этих сообщений.
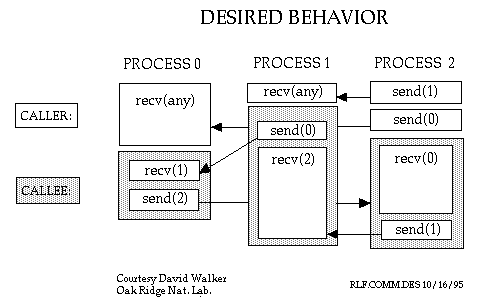
Блоки представляют части параллельных процессов. Время растет сверху вниз на каждой диаграмме. Цифры в круглых скобках НЕ параметры, а номера процессов. Например, send(1) означает отправку сообщения процессу 1. Recv(any) означает получение сообщения от любого процесора. Пользовательский (вызывающий) код находится в белом (незатененном) блоке. Затененный блок (вызываемый) представляет собой пакет (параллельной) библиотеки, вызванной пользователем. Наконец, стрелки представляют собой перемещение сообщения от отправителя получателю.
Нижеприведенная диаграмма показывает то, что бы произошло, если бы случилось то, что мы хотели. В этом случае все работает, как намечено.
Тем не менее, нет никакой гарантии, что события произойдут в этом порядке, так как относительное расписание процессов на различных узлах может меняться от выполнения к выполнению. Предположим, мы изменили третий процесс, добавив некоторые вычисления вначале. Последовательность событий может оказаться следующей:
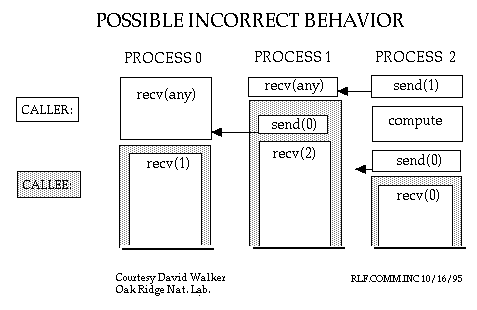
В этом случае коммуникации не происходят как намечено. Первый "receive" в процессе 0 теперь получает "send" из библиотечной функции в процессе 1, а не намеченный (и теперь задержанный) "send" из процесса 2. В результате все три процесса подвисают.
Проблема решается за счет того, что разработчик библиотеки запрашивает новый и уникальный коммуникатор и определяет этот коммуникатор во всех вызовах отослать и получить, которые делаются библиотекой. Это создает библиотечное ("вызываемое") пространство сообщений отдельное от пользовательского ("вызывающего") пространства сообщений.
Можно ли использовать теги, чтобы осуществить отдельные простанства сообщений? Проблема с тегами состоит в том, что их значения задаются программистом и он(а) может использовать тот же тег, что и параллельная библиотека, использующая MPI. С коммуникаторами система, а не программист, назначает идентификацию -- система назначает коммуникатор пользователю и она назначает отличный коммуникатор библиотеке -- так что не возникает возможность перекрытия.
![[Java Applet]](../gifs/try1.gif) Выполнить Java апплет.
Выполнить Java апплет.
4.2 Группы коммуникаторов и процессов
В дополнение к разработке параллельных библиотек, коммуникаторы полезны также в организации коммуникаций внутри приложения. Мы описывали коммуникаторы, которые включают все процессы в приложении. Но программист может также определить подмножество процессов, называемое группой процессов, и прикрепить один или больше коммуникаторов к этой группе процессов. Коммуникация определяет, что коммуникатор будет теперь ограничиваться этими процессами.
В нижеприведенном примере коммуникационным шаблоном является 2-мерная решетка (2D-mesh). Каждый из шести блоков представляет процесс. Каждый процесс должен обменяться данными с соседями выше и ниже, справа и слева. Кодирование этой коммуникации проще если процессы группируются по столбцам (для коммуникаций выше/ниже) и строкам (для коммуникаций направо/налево). Итак, каждый процесс принадлежит трем коммуникаторам, что указывается словами в блоке этого процесса: один коммуникатор на все процессы (мировой коммуникатор по-умолчанию), один коммуникатор на его строку и один коммуникатор на его столбец. Эти коммуникаторы указаны как следует ниже:
| world | коммуникатор для | всех процессов | неокрашен | на диаграмме |
| comm1 | коммуникатор для | строки 1 | желтый | на диаграмме |
| comm2 | коммуникатор для | строки 2 | фиолетовый | на диаграмме |
| comm3 | коммуникатор для | столбца 1 | розовый | на диаграмме |
| comm4 | коммуникатор для | столбца 2 | зеленый | на диаграмме |
| comm5 | коммуникатор для | столбца 3 | голубой | на диаграмме |
Это также прямо связано с использованием коллективных коммуникаторов (охваченных в модуле Коллективные коммуникации MPI I).
|
world, rank0
|
world, rank1
|
world, rank2
|
|
comm1, rank0
|
comm1, rank1
|
comm1, rank2
|
|
comm3, rank0
|
comm4, rank0
|
comm5, rank0
|
|
world, rank3
|
world, rank4
|
world, rank5
|
|
comm2, rank0
|
comm2, rank1
|
comm2, rank2
|
|
comm3, rank1
|
comm4, rank1
|
comm5, rank1
|
Заново напомним аналогию с выпуском исков: одно лицо может иметь счет от электирической и телефонной компаний (2 коммуникатора), но ни одного от водопроводной компании. Электирический коммуникатор может содержать людей, отличающихся от телефонного коммуникатора. Персональный ИН номер (ранг) может изменяться с потребностью (коммуникатором). Итак, критически важно заметить, что ранг, заданный как источник или назначение сообщения есть ранг в точно определенном коммуникаторе.
Компиляция и перенос приложений обсуждает различные способы исполнения выполнения на суперкомпьютере. Пожалуйста, обращайтесь к этому модулю для общих наставлений по созданию исполняемых программ. Для создания параллельной исполняемой программы вам следует включить директорию, содержащую MPI и библиотеки MPI, когда вы активизируете компилятор. Это подразумевает что компилятор и MPICH установлены на машине, где вы компилируете исполняющую программу.
Из командной строки:
Следующие пункты обычно используемых параметров для команды mpirun.
-np определяет число задач на выполнение
-wd определяет рабочую директорию для использования процессом MPI. Это необходимо только тогда, когда текущая директория и желаемая рабочая директория не совпадают.
-h | -help показывает аргументы командной строки для mpirun
-mpi_debug включает дополнительную проверку на входные параметры и дополнительный выход если ошибки возникнут при выполнении.
-maxtime предельное время счета. Обязательный параметр в МСЦ.
Хотя MPI обеспечивает расширенное множество вызовов, функциональная программа на MPI может быть записана с помощью всего шести базовых вызова:
Для удобства программирования и оптимизации кода, вам следует рассмотреть использование других вызовов, таких как описано в модулях по попарной и коллективной коммуникациям.
Коммуникаторы гарантируют уникальные пространства сообщений. В соединении с группами процессов их можно использовать, чтобы ограничить коммуникацию к подмножеству процессов.
Cornell Theory Center Basics of MPI Programming
Богач╦в К.Ю. Основы параллельного программирования. -- М.: БИНОМ. Лаборатория знаний, 2003. -- 342 с.
MPIСH документация в прямом доступе
Литература
![[Quiz]](../gifs/quiz.gif) Пройти тестовый опрос по материалу и подписать его для оценки.
Пройти тестовый опрос по материалу и подписать его для оценки.
![[Exercise]](../gifs/exercise.gif) Лабораторная работа: Основы программирования в MPI
Лабораторная работа: Основы программирования в MPI
|
© 2003
Вычислительный центр им. А.А.Дородницына
Все права защищены. |
|
