рбтбммемшоще чщюйумеойс ч MATLAB
й йи ртймпцеойс л нпдемйтпчбойа ьлпопнйлй
о.о. пМЕОЕЧ, б.н. юЕТОЕГПЧ
рПСЧМЕОЙЕ НОПЗПСДЕТОЩИ РТПГЕУУПТПЧ РПВХДЙМП УПЪДБФЕМЕК УЙУФЕНЩ MATLAB Й ДТХЗЙИ НБФЕНБФЙЮЕУЛЙИ РТПЗТБННОЩИ УЙУФЕН ХДЕМСФШ ВПМШЫЕ ЧОЙНБОЙС РБТБММЕМШОЩН БУРЕЛФБН ЧЩЮЙУМЕОЙК, ЮФП ЧМЕЮЕФ ВЩУФТЩЕ ЙЪНЕОЕОЙС ЬФЙИ УЙУФЕН. уППФЧЕФУФЧЕООП ХЧЕМЙЮЙЧБАФУС РПФЕОГЙБМШОЩЕ ЧПЪНПЦОПУФЙ ЙУРПМШЪПЧБОЙС РБТБММЕМШОЩИ ЧЩЮЙУМЕОЙК Ч ТБЪМЙЮОЩИ РТЙЛМБДОЩИ ПВМБУФСИ. нПОПЗТБЖЙС [1] СЧМСЕФУС РЕТЧПК ТБВПФПК, ПРЙУЩЧБАЭЕК ТБУРТЕДЕМЕООЩЕ Й РБТБММЕМШОЩЕ ЧЩЮЙУМЕОЙС Ч УТЕДЕ MATLAB ОБ НОПЗПСДЕТОЩИ Й НОПЗПРТПГЕУУПТОЩИ УЙУФЕНБИ Й ЙИ РТЙМПЦЕОЙС Л ЪБДБЮБН НБФЕНБФЙЮЕУЛПЗП НПДЕМЙТПЧБОЙС Ч ЬЛПОПНЙЛЕ. ч [1] ЙЪМПЦЕОБ ФБЛЦЕ ФЕИОПМПЗЙС ОБУФТПКЛЙ НОПЗПРТПГЕУУПТОЩИ ЧЩЮЙУМЙФЕМШОЩИ УЙУФЕН ДМС ЙУРПМШЪПЧБОЙС MATLAB.
фЕИОПМПЗЙС ТБУРТЕДЕМЕООЩИ Й РБТБММЕМШОЩИ ЧЩЮЙУМЕОЙК ТЕБМЙЪПЧБОБ ЛПНРБОЙЕК MathWorks У РПНПЭША ДЧХИ ЧЪБЙНПУЧСЪБООЩИ РБЛЕФПЧ ТБУЫЙТЕОЙК (РТЙМПЦЕОЙК): MATLAB Distributed Computing toolbox [2] Й MATLAB Distributed Computing Engine (MDCE) [3]. уИЕНБ ТБУРТЕДЕМЕООЩИ ЧЩЮЙУМЕОЙК MATLAB ТЕБМЙЪПЧБОБ ФБЛЙН ПВТБЪПН, ЮФП РМБОЙТПЧЭЙЛ ЪБРТБЫЙЧБЕФ ТЕУХТУЩ ТБВПЮЙИ РТПГЕУУПЧ. ч ЛБЮЕУФЧЕ РТПГЕУУБ, Ч ЮБУФОПУФЙ, НПЦЕФ ЧЩУФХРБФШ ХЪЕМ ЛМБУФЕТБ, РТПГЕУУПТ УЙННЕФТЙЮОПК НОПЗПРТПГЕУУПТОПК УЙУФЕНЩ, СДТП НОПЗПСДЕТОПЗП РТПГЕУУПТБ. чЪБЙНПДЕКУФЧЙС РТПЙУИПДСФ ЮЕТЕЪ ЪБРХЭЕООХА ОБ ЛБЦДПК НБЫЙОЕ УМХЦВХ MDCE.
нЕЦРТПГЕУУПТОЩЕ ПВНЕОЩ ТЕБМЙЪПЧБОЩ УТЕДУФЧБНЙ ВЙВМЙПФЕЛЙ MPI mpich2. нЕФПДПМПЗЙС ЛПНРБОЙЙ Mathworks ЧЩДЕМСЕФ ПФДЕМШОП ТБУРТЕДЕМЕООЩЕ Й РБТБММЕМШОЩЕ ЪБДБЮЙ. рТЙНЕТПН РЕТЧЩИ СЧМСЕФУС ТБУРТЕДЕМЕООПЕ РТЕДУФБЧМЕОЙЕ НБФТЙГЩ Ч ЧЙДЕ РТПЙЪЧЕДЕОЙС ОЙЦОЕК ФТЕХЗПМШОПК НБФТЙГЩ L Й ЧЕТИОЕК ФТЕХЗПМШОПК НБФТЙГЩ U (LU ТБЪМПЦЕОЙЕ НБФТЙГЩ), ЛПЗДБ НБФТЙГБ ТБЪДЕМСЕФУС ОБ ВМПЛЙ БЧФПНБФЙЮЕУЛЙ УТЕДУФЧБНЙ MATLAB. лП ЧФПТЩН ПФОПУСФУС ЪБДБЮЙ, Ч ЛПФПТЩИ НЕЦРТПГЕУУПТОЩЕ ПВНЕОЩ ЪБДБОЩ СЧОП У ЙУРПМШЪПЧБОЙЕН УРЕГЙБМШОЩИ РТПГЕДХТ, БОБМПЗЙЮОЩИ УТЕДУФЧБН MPI [1,2].
рТЕДУФБЧЙН ЪДЕУШ ОЕЛПФПТЩЕ БУРЕЛФЩ РТЙМПЦЕОЙС РБТБММЕМШОЩИ ЧЩЮЙУМЕОЙК Ч MATLAB Л ТЕЫЕОЙА ЪБДБЮЙ ЙДЕОФЙЖЙЛБГЙЙ РБТБНЕФТПЧ Ч ЬЛПОПНЙЮЕУЛПК НПДЕМЙ. нПЦОП РТЙНЕОСФШ РБТБММЕМШОЩЕ ЧЩЮЙУМЕОЙС ДМС ТЕЫЕОЙС ФТБДЙГЙПООЩИ ЪБДБЮ НБФЕНБФЙЮЕУЛПЗП НПДЕМЙТПЧБОЙС УМПЦОЩИ УЙУФЕН, ОБРТЙНЕТ, ФБЛЙИ ЛБЛ ХУЛПТЕОЙЕ ТБУЮЕФПЧ РТЙ РТПЧЕДЕОЙЙ ЮЙУМЕООЩИ ЬЛУРЕТЙНЕОФПЧ У НПДЕМША ЬЛПОПНЙЛЙ УФТБОЩ ЙМЙ ТЕЗЙПОБ, Б НПЦОП Й ОЕ РТЙНЕОСФШ, ЕУМЙ Ч ПВЭЕН ЧТЕНЕОЙ РПУФТПЕОЙС НПДЕМЙ ОЕРПУТЕДУФЧЕООЩК ТБУЮЕФ УПУФБЧМСЕФ ПФОПУЙФЕМШОП ОЕВПМШЫПЕ ЧТЕНС. оХЦОП РТЙНЕОСФШ РБТБММЕМШОЩЕ ЧЩЮЙУМЕОЙС ДМС ТЕЫЕОЙС ФБЛЙИ ЪБДБЮ, ЛПФПТЩЕ ДТХЗЙН УРПУПВПН ТЕЫЙФШ МЙВП ОЕЧПЪНПЦОП, МЙВП ЮТЕЪЧЩЮБКОП ФТХДОП. ьФП ТБУЫЙТСЕФ ЗТБОЙГЩ ПВМБУФЙ ОБХЮОЩИ ЙУУМЕДПЧБОЙК Й РТЙМПЦЕОЙК Ч ВЙЪОЕУЕ, Ч ЛПФПТЩИ ЬЖЖЕЛФЙЧОП РТЙНЕОСФШ НЕФПДЩ НБФЕНБФЙЮЕУЛПЗП НПДЕМЙТПЧБОЙС.
йДЕОФЙЖЙЛБГЙС УМПЦОПК НБФЕНБФЙЮЕУЛПК НПДЕМЙ ФПК ЙМЙ ЙОПК ЬЛПОПНЙЮЕУЛПК УЙУФЕНЩ, ЪБЛМАЮБАЭБСУС Ч ПРТЕДЕМЕОЙЙ ЧОЕЫОЙИ РБТБНЕФТПЧ ЬФПК НПДЕМЙ, СЧМСЕФУС ПДОПК ЙЪ ПУОПЧОЩИ ЪБДБЮ, ЗДЕ РБТБММЕМШОЩЕ ЧЩЮЙУМЕОЙС РПЪЧПМСАФ ОБИПДЙФШ ТЕЫЕОЙС, ЛПФПТЩЕ ВЕЪ РТЙНЕОЕОЙС РБТБММЕМШОЩИ ЧЩЮЙУМЕОЙК ВЩМП ОЕЧПЪНПЦОП ОБКФЙ ФПЮОП. рТПВМЕНЩ, ЧПЪОЙЛБАЭЙЕ РТЙ ТЕЫЕОЙЙ ЬФПК ЪБДБЮЙ, ВХДХФ ЪДЕУШ ТБУУНПФТЕОЩ ОБ РТЙНЕТЕ УРЕГЙБМШОП РПУФТПЕООПК РТПУФЕКЫЕК ЬЛПОПНЕФТЙЮЕУЛПК ДЙОБНЙЮЕУЛПК НПДЕМЙ УПЧТЕНЕООПК ТПУУЙКУЛПК ЬЛПОПНЙЛЙ.
пЗТПНОЩК ЧПЪНПЦОЩК ОБВПТ УПЮЕФБОЙК ЪОБЮЕОЙК РБТБНЕФТПЧ ОЕ РПЪЧПМСМ ДП РПСЧМЕОЙС ЧЩУПЛПРТПЙЪЧПДЙФЕМШОЩИ РБТБММЕМШОЩИ БТИЙФЕЛФХТ ФПЮОП ПРТЕДЕМСФШ ЬФЙ ЪОБЮЕОЙС. йУРПМШЪПЧБОЙЕ ЧЩУПЛПРТПЙЪЧПДЙФЕМШОЩИ РБТБММЕМШОЩИ ЧЩЮЙУМЕОЙК ВМБЗПДБТС ДПУФБФПЮОП РПМОПНХ РЕТЕВПТХ РПЪЧПМСЕФ ФПЮОП ТЕЫЙФШ ЪБДБЮХ ЙДЕОФЙЖЙЛБГЙЙ РБТБНЕФТПЧ УМПЦОЩИ НБФЕНБФЙЮЕУЛЙИ НПДЕМЕК ЬЛПОПНЙЮЕУЛЙИ УЙУФЕН. дЕМП Ч ФПН, ЮФП Ч НПДЕМСИ ЬЛПОПНЙЛЙ ЙНЕЕФУС ОЕНБМП РБТБНЕФТПЧ, ЛПФПТЩЕ ОЕ ХДБЕФУС ОБКФЙ ОБРТСНХА ЙЪ ДБООЩИ ЬЛПОПНЙЮЕУЛПК УФБФЙУФЙЛЙ. ч УМХЮБЕ ЦЕ, ЛПЗДБ ДБООЩИ УФБФЙУФЙЛЙ ИЧБФБЕФ, ЛБЮЕУФЧП ЙУИПДОЩИ УФБФЙУФЙЮЕУЛЙИ ДБООЩИ, ЛБЛ РТБЧЙМП, ФБЛПЧП, ЮФП ЙИ ИЧБФБЕФ ФПМШЛП ДМС ПРТЕДЕМЕОЙС ЙОФЕТЧБМПЧ, Ч ЛПФПТЩЕ РПРБДБАФ РБТБНЕФТЩ НПДЕМЙ. лТПНЕ ФПЗП, Й ОБЮБМШОЩЕ ЪОБЮЕОЙС ОЕЛПФПТЩИ РЕТЕНЕООЩИ НПДЕМЙ ЮБУФП ФПЮОП ОЕЙЪЧЕУФОЩ Й РПЬФПНХ ДПМЦОЩ ТБУУНБФТЙЧБФШУС ЛБЛ ФБЛПЗП ТПДБ РБТБНЕФТЩ.
оЕЙЪЧЕУФОЩЕ РБТБНЕФТЩ ЬЛПОПНЙЮЕУЛПК НПДЕМЙ ПРТЕДЕМСЕН ЛПУЧЕООЩН ПВТБЪПН, УТБЧОЙЧБС ТБУУЮЙФБООЩЕ У РПНПЭША НПДЕМЙ ЧЩИПДОЩЕ ЧТЕНЕООЩЕ ТСДЩ ЕЕ РЕТЕНЕООЩИ У ДПУФХРОЩНЙ УФБФЙУФЙЮЕУЛЙНЙ ЧТЕНЕООЩНЙ ТСДБНЙ ДМС ЬФЙИ РЕТЕНЕООЩИ Ч ЙЪХЮБЕНПК ЬЛПОПНЙЮЕУЛПК УЙУФЕНЕ. нБФЕТЙБМЩ ЙУУМЕДПЧБОЙС ЙЪМБЗБАФУС ФБЛЙН ПВТБЪПН, ЮФПВЩ ЙИ МЕЗЛП НПЦОП ВЩМП ПВПВЭЙФШ ДМС ЙУРПМШЪПЧБОЙС Ч ЪБДБЮБИ ЙДЕОФЙЖЙЛБГЙЙ ВПМЕЕ УМПЦОЩИ НПДЕМЕК ЬЛПОПНЙЮЕУЛЙИ УЙУФЕН Й, ЧППВЭЕ, Ч ЪБДБЮБИ ЙДЕОФЙЖЙЛБГЙЙ НБФЕНБФЙЮЕУЛЙИ НПДЕМЕК УМПЦОЩИ РТПГЕУУПЧ Й УЙУФЕН.
тБУУНПФТЙН РТПУФЕКЫХА ЬЛПОПНЕФТЙЮЕУЛХА НПДЕМШ ЬЛПОПНЙЛЙ, ЮФПВЩ ОБ ОЕК РТПДЕНПОУФТЙТПЧБФШ ЧУЕ ФЕ ПУОПЧОЩЕ ЪБДБЮЙ, ЛПФПТЩЕ РТЙИПДЙФУС ТЕЫБФШ ЙУУМЕДПЧБФЕМА РТЙ ЙДЕОФЙЖЙЛБГЙЙ ЧОЕЫОЙИ РБТБНЕФТПЧ НБФЕНБФЙЮЕУЛЙИ НПДЕМЕК ЬЛПОПНЙЛЙ У РПНПЭША РБТБММЕМШОЩИ ЧЩЮЙУМЕОЙК. ьФБ НПДЕМШ ОЕНОПЗП ПФМЙЮБЕФУС ПФ УФБОДБТФОПК ЪБНЛОХФПК РТПУФЕКЫЕК НПДЕМЙ ЬЛПОПНЙЛЙ УФТБОЩ, ПРЙУБООПК ЧП НОПЗЙИ ХЮЕВОЙЛБИ РП НБФЕНБФЙЮЕУЛПК ЬЛПОПНЙЛЕ, ДМС ФПЗП ЮФПВЩ ХЮЕУФШ ЧОЕЫОЕФПТЗПЧЩК ПВПТПФ Й ЙЪНЕОЕОЙЕ ПФОПУЙФЕМШОЩИ ГЕО ОБ УПУФБЧМСАЭЙЕ ПУОПЧОПЗП НБЛТПЬЛПОПНЙЮЕУЛПЗП ВБМБОУБ, РТПЙУИПДСЭЕЕ Ч УПЧТЕНЕООПК ЬЛПОПНЙЛЕ тПУУЙЙ.
рХУФШ ЧБМПЧПК ЧОХФТЕООЙК РТПДХЛФ (ччр) ПРТЕДЕМСЕФУС ПДОПТПДОПК РТПЙЪЧПДУФЧЕООПК ЖХОЛГЙЕК У РПУФПСООПК ЬМБУФЙЮОПУФША ЪБНЕЭЕОЙС (CES-ЖХОЛГЙЕК). пВЩЮОП РБТБНЕФТЩ РТПЙЪЧПДУФЧЕООПК ЖХОЛГЙЙ ПРТЕДЕМСАФ У РПНПЭША ОЕМЙОЕКОПЗП НЕФПДБ ОБЙНЕОШЫЙИ ЛЧБДТБФПЧ РП ДБООЩН ЬЛПОПНЙЮЕУЛПК УФБФЙУФЙЛЙ ДМС ЧТЕНЕООЩИ ТСДПЧ РЕТЕНЕООЩИ, ОЕРПУТЕДУФЧЕООП ЧИПДСЭЙИ Ч РТПЙЪЧПДУФЧЕООХА ЖХОЛГЙА. оП, Ч ОБЫЕН УМХЮБЕ ЪОБЮЕОЙС ЛБРЙФБМБ, РТЕДУФБЧМСЕНЩЕ УФБФЙУФЙЮЕУЛЙНЙ ПТЗБОБНЙ, ЧЩЪЩЧБАФ ВПМШЫПЕ УПНОЕОЙЕ [1, 4]. уФБФЙУФЙЮЕУЛЙЕ ДБООЩЕ РП ЛБРЙФБМХ РТБЛФЙЮЕУЛЙ ОЕ НЕОСАФУС ПФ ЗПДБ Л ЗПДХ. жБЛФЙЮЕУЛЙ ЬФЙ ЪОБЮЕОЙС РТЕДУФБЧМСАФ УПВПК ЛБРЙФБМ, УПЪДБООЩК ЧП ЧТЕНЕОБ ууут Й Ч ОБУФПСЭЕЕ ЧТЕНС Ч ВПМШЫПК УФЕРЕОЙ РТЕДУФБЧМСЕФ УПВПК "ВЕУРМБФОЩЕ" ТЕУХТУЩ, РПДПВОЩЕ ОЕЛПФПТЩН РТЙТПДОЩН ТЕУХТУБН, ЛПФПТЩЕ ЕЭЕ НПЦОП ЙУРПМШЪПЧБФШ ВЕЪ ПРМБФЩ (ЧПЪДХИ, ЧПДБ). оБ ЧЩРХУЛЕ УЛБЪЩЧБЕФУС ЧМЙСОЙЕ ФПМШЛП ЛБРЙФБМБ, ХЦЕ ЧПЧМЕЮЕООЩК Ч РТПГЕУУ ЧПУРТПЙЪЧПДУФЧБ, ЙНЕАЭЕЗП ПВЯЕЛФЙЧОХА УФПЙНПУФШ. лБРЙФБМ СЧМСЕФУС ОЕЛПК ЬЖЖЕЛФЙЧОПК УФПЙНПУФША РТПЙЪЧПДУФЧЕООЩИ ЖПОДПЧ, ЛПФПТХА ОБДП ПГЕОЙФШ.
рТЕДРПМПЦЙН, ЮФП ФТХД, ЙЪНЕТСЕНЩК Ч ТБУУНБФТЙЧБЕНПК НПДЕМЙ УТЕДОЕЗПДПЧЩН ЮЙУМПН ЪБОСФЩИ Ч ОБТПДОПН ИПЪСКУФЧЕ (Ч ПФМЙЮЙЕ ПФ [4], ЗДЕ ФТХД ЙЪНЕТСЕФУС ЮЙУМПН ПФТБВПФБООЩИ ЮБУПЧ ДМС ХЮЕФБ УЕЪПООЩИ ЛПМЕВБОЙК ПФ ЛЧБТФБМБ Л ЛЧБТФБМХ), ТБУФЕФ У РПУФПСООЩН ФЕНРПН.
вХДЕН УЮЙФБФШ, ЮФП ЛБРЙФБМ НЕОСЕФУС Ч УЙМХ ПВЩЮОП РТЙНЕОСЕНПЗП Ч НБЛТПЬЛПОПНЙЮЕУЛЙИ НПДЕМСИ УФБОДБТФОПЗП ДЙОБНЙЮЕУЛПЗП ХТБЧОЕОЙС, Ч ЛПФПТПН ПВЯЕН ЙОЧЕУФЙГЙК ТБЧЕО УХННЕ УЛПТПУФЙ ЙЪНЕОЕОЙС ЛБРЙФБМБ Й ОЕЛЙИ ПФЮЙУМЕОЙК, РТПРПТГЙПОБМШОЩИ ЛБРЙФБМХ, ЛПФПТЩЕ ПВЩЮОП ПФПЦДЕУФЧМСАФ У БНПТФЙЪБГЙПООЩНЙ. лПЬЖЖЙГЙЕОФ РТПРПТГЙПОБМШОПУФЙ ПФЮЙУМЕОЙК Й ЛБРЙФБМБ - ФЕНР ЧЩВЩФЙС - РТЙ ТБУУНПФТЕОЙЙ ЬЖЖЕЛФЙЧОПЗП ЛБРЙФБМБ, ТЕБМШОП ЧПЧМЕЮЕООПЗП Ч РТПГЕУУ ЧПУРТПЙЪЧПДУФЧБ Ч УПЧТЕНЕООПК ЬЛПОПНЙЮЕУЛПК УЙФХБГЙЙ Ч тПУУЙЙ, ВХДЕФ ОЙЦЕ, РПУЛПМШЛХ Ч РТПГЕУУ ЧПУРТПЙЪЧПДУФЧБ ЧПЧМЕЛБЕФУС ЮБУФШ РТПЙЪЧПДУФЧЕООЩИ ЖПОДПЧ, ДПУФБЧЫЙИУС ОЩОЕЫОЕК ЬЛПОПНЙЛЕ ПФ УПЧЕФУЛЙИ ЧТЕНЕО, ЮФП ДБЕФ ВПМШЫХА УЛПТПУФШ ЙЪНЕОЕОЙС ЛБРЙФБМБ, ЮЕН ПВЕУРЕЮЙЧБАФ ЙОЧЕУФЙГЙЙ. ьФПФ ФЕНР НПЦЕФ ВЩФШ ДБЦЕ ПФТЙГБФЕМШОЩН, ЕУМЙ Ч РТПГЕУУ РТПЙЪЧПДУФЧБ ЧПЧМЕЛБЕФУС ТБОЕЕ ОЕ ЙУРПМШЪХЕНПЗП ЛБРЙФБМБ ВПМШЫЕ, ЮЕН БНПТФЙЪЙТХЕФУС.
рХУФШ Ч ЛБЦДЩК НПНЕОФ ЧТЕНЕОЙ t ЧЩРПМОСЕФУС ПУОПЧОПК НБЛТПЬЛПОПНЙЮЕУЛЙК РТПДХЛФПЧЩК ВБМБОУ Ч ФЕЛХЭЙИ ГЕОБИ: УХННБ ЧЩРХУЛБ ччр Й ЙНРПТФБ ТБЧОБ УХННЕ ЛПОЕЮОПЗП РПФТЕВМЕОЙС ОБУЕМЕОЙС, РТБЧЙФЕМШУФЧБ Й ОЕЛПННЕТЮЕУЛЙИ РТЕДРТЙСФЙК, У ДПВБЧМЕОЙЕН ЮЙУФПЗП ОБЛПРМЕОЙС ВПЗБФУФЧ Й РТЙТПУФБ НБФЕТЙБМШОЩИ ЪБРБУПЧ, ЙОЧЕУФЙГЙК Ч ПУОПЧОПК ЛБРЙФБМ Й ЬЛУРПТФБ. рПУЛПМШЛХ ОБУ ЙОФЕТЕУХАФ ЪОБЮЕОЙС ЧЕМЙЮЙО ЧЩРХУЛБ, ЙОЧЕУФЙГЙК, ЬЛУРПТФБ Й ЙНРПТФБ, ЧЩТБЦЕООЩЕ Ч РПУФПСООЩИ ГЕОБИ, НПЦОП РПМШЪХСУШ ДБООЩНЙ УФБФЙУФЙЛЙ РЕТЕКФЙ Л РТПДХЛФПЧПНХ ВБМБОУХ, ЧЩТБЦЕООПНХ Ч ЙОДЕЛУБИ ПФОПУЙФЕМШОЩИ ГЕО.
дМС ЪБНЩЛБОЙС НПДЕМЙ РТЕДРПМПЦЙН, ЮФП ПВЯЕНЩ ЙОЧЕУФЙГЙК, ЬЛУРПТФБ Й ЙНРПТФБ Ч РПУФПСООЩИ ГЕОБИ 2000 ЗПДБ ПРТЕДЕМСАФУС РПУФПСООЩНЙ ЛПЬЖЖЙГЙЕОФБНЙ РТПРПТГЙПОБМШОПУФЙ ЙИ ЧЩРХУЛХ (ччр), ФБЛЦЕ ЧЩТБЦЕООПНХ Ч РПУФПСООЩИ ГЕОБИ. ьФЙ РТЕДРПМПЦЕОЙС РПДФЧЕТЦДБАФУС УФБФЙУФЙЮЕУЛЙНЙ ДБООЩНЙ 2000-2006 ЗПДПЧ. фБЛЙН ПВТБЪПН, НЩ РПМХЮБЕН РТПУФЕКЫХА ДЙОБНЙЮЕУЛХА НПДЕМШ ЬЛПОПНЙЛЙ тПУУЙЙ.
йФБЛ, ДМС ЙДЕОФЙЖЙЛБГЙЙ НПДЕМЙ ОБДП ЪБДБФШ ЙЪНЕОЕОЙЕ ЧОЕЫОЙИ ЙОФЕОУЙЧОЩИ РБТБНЕФТПЧ НПДЕМЙ. ьФП ЧТЕНЕООЩЕ ТСДЩ ДМС ФТЕИ ПФОПУЙФЕМШОЩИ ГЕО (ОБ ЬЛУРПТФ, ОБ ЙНРПТФ Й ОБ ЙОЧЕУФЙГЙЙ), УЕНШ РПУФПСООЩИ РБТБНЕФТПЧ (ДЧБ РБТБНЕФТБ РТПЙЪЧПДУФЧЕООПК ЖХОЛГЙЙ CES, ФЕНР ТПУФБ ЪБОСФЩИ, ФЕНР УРЙУБОЙС ЛБРЙФБМБ, ФТЙ ЛПЬЖЖЙГЙЕОФБ РТПРПТГЙПОБМШОПУФЙ ЙОЧЕУФЙГЙК, ЬЛУРПТФБ Й ЙНРПТФБ ЧЩРХУЛХ) Й ФТЙ ОБЮБМШОЩИ ЪОБЮЕОЙС (ДМС ЧЩРХУЛБ, ДМС ЛБРЙФБМБ Й ДМС ФТХДБ). ъБДБФШ ЧОЕЫОЙЕ РБТБНЕФТЩ ОБДП ФБЛЙН ПВТБЪПН, ЮФПВЩ ТБУЮЕФОЩЕ ЧТЕНЕООЩЕ ТСДЩ НБЛТПРПЛБЪБФЕМЕК НПДЕМЙ ВЩМЙ ВМЙЪЛЙ Л УФБФЙУФЙЮЕУЛЙН ЧТЕНЕООЩН ТСДБН УППФЧЕФУФЧХАЭЙИ НБЛТПРПЛБЪБФЕМЕК ЬЛПОПНЙЛЙ тПУУЙЙ. дМС УХЭЕУФЧХАЭЕК Ч ОБУФПСЭЕЕ ЧТЕНС ЧЩЮЙУМЙФЕМШОПК ФЕИОЙЛЙ ДБЦЕ ЬФБ РТПУФЕКЫБС НПДЕМШ ОЕ НПЦЕФ ВЩФШ ЙДЕОФЙЖЙГЙТПЧБОБ РТСНЩН РЕТЕВПТПН. рПЬФПНХ ВПМШЫХА ЮБУФШ РБТБНЕФТПЧ, ДМС ЛПФПТЩИ ЬФП НПЦОП УДЕМБФШ, ПРТЕДЕМЙН ФТБДЙГЙПООЩН УРПУПВПН - РПУТЕДУФЧПН УФБФЙУФЙЮЕУЛЙИ ПГЕОПЛ РП ДБООЩН жЕДЕТБМШОПК УМХЦВЩ ЗПУХДБТУФЧЕООПК УФБФЙУФЙЛЙ тж (www.gks.ru) ДМС ЛБЦДПЗП ПФДЕМШОПЗП УППФОПЫЕОЙС НПДЕМЙ. ч ТЕЪХМШФБФЕ Х ОБУ ПУФБОХФУС ЮЕФЩТЕ РБТБНЕФТБ, ЛПФПТЩЕ ОБРТСНХА ЙЪ УФБФЙУФЙЛЙ ПРТЕДЕМЙФШ ОЕЧПЪНПЦОП ЙЪ-ЪБ ПФУХФУФЧЙС ДПУФПЧЕТОЩИ ДБООЩИ РП ЛБРЙФБМХ: ДЧБ РБТБНЕФТБ РТПЙЪЧПДУФЧЕООПК ЖХОЛГЙЙ, ОБЮБМШОПЕ ЪОБЮЕОЙЕ ЛБРЙФБМБ Й ФЕНР ЕЗП ЧЩВЩФЙС. ьФХ ЪБДБЮХ НПЦОП ТЕЫЙФШ, ЙУРПМШЪХС РБТБММЕМШОЩЕ ЧЩЮЙУМЕОЙС Ч УЙУФЕНЕ MATLAB.
чТЕНЕООЩЕ ТСДЩ УЮЙФБАФУС РПИПЦЙНЙ, ЕУМЙ ПОЙ ВМЙЪЛЙ ЛБЛ ЖХОЛГЙЙ ЧТЕНЕОЙ (ДТХЗЙНЙ УМПЧБНЙ, НЕЦДХ ЪОБЮЕОЙСНЙ ЧТЕНЕООЩИ ТСДПЧ УХЭЕУФЧХЕФ УЙМШОБС, ЧПЪНПЦОП ОЕМЙОЕКОБС, УЧСЪШ). вХДЕН ЙУРПМШЪПЧБФШ ЛПЬЖЖЙГЙЕОФ ЛПТТЕМСГЙЙ рЙТУПОБ D(X, Y), ЛПФПТЩК СЧМСЕФУС НЕТПК УЙМЩ Й ОБРТБЧМЕООПУФЙ МЙОЕКОПК УЧСЪЙ НЕЦДХ УТБЧОЙЧБЕНЩНЙ ЧТЕНЕООЩНЙ ТСДБНЙ X Й Y, Й ЮЕН ПО ВМЙЦЕ Л ЕДЙОЙГЕ, ФЕН ВПМЕЕ УИПЦЕ РПЧЕДЕОЙЕ ЬФЙИ ТСДПЧ. рТЙ ЬФПН УМЕДХЕФ ХЮЙФЩЧБФШ, ЮФП ЙОЖМСГЙПООБС УПУФБЧМСАЭБС НПЦЕФ РТЕХЧЕМЙЮЙЧБФШ МЙОЕКОХА УЧСЪШ ТСДПЧ, РПЬФПНХ РТЙ ЙУРПМШЪПЧБОЙЙ ЛПЬЖЖЙГЙЕОФБ ЛПТТЕМСГЙЙ ОХЦОП УТБЧОЙЧБФШ РПЛБЪБФЕМЙ Ч ТЕБМШОЩИ ЧЕМЙЮЙОБИ. йОДЕЛУ фЕКМБ E(X, Y) ЙЪНЕТСЕФ ОЕУПЧРБДЕОЙЕ ЧТЕНЕООЩИ ТСДПЧ X(t) Й Y(t) Й ЮЕН ВМЙЦЕ ПО Л ОХМА, ФЕН ВМЙЦЕ УТБЧОЙЧБЕНЩЕ ТСДЩ. дМС ХДПВУФЧБ РТПЧЕДЕОЙС ТБУЮЕФПЧ УП УЧЕТФЛПК ЛТЙФЕТЙЕЧ, Ч ДБМШОЕКЫЕН ЧНЕУФП ЙОДЕЛУБ фЕКМБ ВХДЕН ЙУРПМШЪПЧБФШ ЛПЬЖЖЙГЙЕОФ ВМЙЪПУФЙ U(X, Y) = 1 - E(X, Y). юЕН ЧЩЫЕ ПО (ЮЕН ВМЙЦЕ ПО Л ЕДЙОЙГЕ), ФЕН ВПМЕЕ ВМЙЪЛЙ ТСДЩ.
дМС ПДОПЪОБЮОПУФЙ ЧЩВПТБ ПРФЙНБМШОПЗП ЧБТЙБОФБ Ч ЛБЮЕУФЧЕ УЧЕТФЛЙ ЛПЬЖЖЙГЙЕОФПЧ ВМЙЪПУФЙ Й ЛПТТЕМСГЙЙ ЧПЪШНЕН УТЕДОЕЗЕПНЕФТЙЮЕУЛХА ЧЕМЙЮЙОХ ЧУЕИ ЛПЬЖЖЙГЙЕОФПЧ ДМС УТБЧОЙЧБЕНЩИ ТСДПЧ. рТЙ ЬФПН РТЙ РЕТЕВПТЕ УМЕДХЕФ ТБУУНБФТЙЧБФШ ФПМШЛП ФЕ ЧБТЙБОФЩ ЪОБЮЕОЙК РБТБНЕФТПЧ, РТЙ ЛПФПТЩИ ЛПЬЖЖЙГЙЕОФЩ ВМЙЪПУФЙ Й ЛПТТЕМСГЙЙ ЧЩЫЕ ОЕЛПФПТЩИ ЪБДБООЩИ РПМПЦЙФЕМШОЩИ ЧЕМЙЮЙО.
юЙУМЕООБС ТЕБМЙЪБГЙС ЪБДБЮЙ ЙДЕОФЙЖЙЛБГЙЙ
оБЫБ ПУОПЧОБС ЪБДБЮБ - РПДПВТБФШ ФБЛПК ЧТЕНЕООПК ТСД ДМС ЛБРЙФБМБ, ЛПФПТЩК ОБЙМХЮЫЙН ПВТБЪПН РТЙВМЙЦБЕФ ЧТЕНЕООЩЕ ТСДЩ НБЛТПРПЛБЪБФЕМЕК, ТБУУЮЙФБООЩИ РП НПДЕМЙ, Л ЙИ УФБФЙУФЙЮЕУЛЙН БОБМПЗБН. дМС РПЙУЛБ РБТБНЕФТПЧ У РПНПЭША РБТБММЕМШОЩИ ЧЩЮЙУМЕОЙК ОБДП ЧЪСФШ УЕФЛХ ОБ ЙОФЕТЧБМЕ ЙЪНЕОЕОЙС ЛБЦДПЗП РБТБНЕФТБ, ХУФТПЙФШ РЕТЕВПТ ЧУЕИ ЧПЪНПЦОЩИ УПЮЕФБОЙК, ТБУРБТБММЕМЙФШ ЬФПФ РЕТЕВПТ ОБ ДПУФХРОПЕ ЮЙУМП РТПГЕУУПЧ. оБ ЛБЦДПН ЙЪ РТПГЕУУПЧ ПФВТПУЙФШ ЧБТЙБОФЩ, Ч ЛПФПТЩИ ЛПЬЖЖЙГЙЕОФЩ ЛПТТЕМСГЙЙ Й ВМЙЪПУФЙ ОЕ РТЕЧЩЫБАФ 0.4. чЩВТБФШ ЧБТЙБОФ У ОБЙВПМШЫЕК УЧЕТФЛПК.
уИЕНБ БМЗПТЙФНБ
1. ч ГЙЛМЕ РП УЕФЛБН ДМС ЙОФЕТЧБМПЧ ЪБДБОЙС РБТБНЕФТПЧ ЪБДБАФУС ЙИ ЪОБЮЕОЙС ЮЕТЕЪ ТБЧОЩК ЙОФЕТЧБМ (ЬФЙ ГЙЛМЩ Й ОБДП ТБУРБТБММЕМЙФШ ДМС ТБУЮЕФБ ТБЪОЩИ ЗТХРР ОБВПТПЧ РБТБНЕФТПЧ)
2. дМС ЛБЦДПЗП ОБВПТБ РБТБНЕФТПЧ ТБУУЮЙФЩЧБАФУС ЧТЕНЕООЩЕ ТСДЩ ЧУЕИ НБЛТПРПЛБЪБФЕМЕК – ФТХДБ, ЧЩРХУЛБ, ЙНРПТФБ, ЬЛУРПТФБ, РПФТЕВМЕОЙС, ЙОЧЕУФЙГЙК.
3. дМС ЛБЦДПЗП НБЛТПРПЛБЪБФЕМС, ХЮБУФЧХАЭЕЗП Ч УТБЧОЕОЙЙ ТБУЮЕФОЩИ Й УФБФЙУФЙЮЕУЛЙИ ДБООЩИ, ТБУУЮЙФЩЧБАФУС ЛТЙФЕТЙЙ ВМЙЪПУФЙ $U$ Й ЛПТТЕМСГЙЙ $D$ НЕЦДХ ТБУЮЕФОЩНЙ Й УФБФЙУФЙЮЕУЛЙНЙ ЧТЕНЕООЩНЙ ТСДБНЙ ОБ РТПНЕЦХФЛЕ ЧТЕНЕОЙ 2001-2006.
4. тБУУЮЙФЩЧБЕН УЧЕТФЛХ ЛТЙФЕТЙЕЧ.
5. ч ЛБЦДПН РТПГЕУУЕ ПРТЕДЕМСЕН МХЮЫЙК ОПНЕТ ОБВПТБ РБТБНЕФТПЧ РП ЛТЙФЕТЙА.
6. оБ РТПГЕУУЕ НБУФЕТЕ ЧЩВЙТБЕН МХЮЫЙК ОПНЕТ ЙЪ МХЮЫЙИ, РПМХЮЕООЩИ ПФ ТБВПЮЙИ РТПГЕУУПЧ. тБУУЮЙФЩЧБЕН Й ТБУРЕЮБФЩЧБЕН ДМС ОЕЗП ЧТЕНЕООЩЕ ТСДЩ ЧУЕИ РПЛБЪБФЕМЕК Й ЪОБЮЕОЙС ЧУЕИ ЛТЙФЕТЙЕЧ.
пРЙУБООЩК БМЗПТЙФН ЙДЕОФЙЖЙЛБГЙЙ ДЙОБНЙЮЕУЛПК УЙУФЕНЩ ТЕБМЙЪПЧБО Ч ЧЙДЕ ПУОПЧОПЗП ЖБКМБ УГЕОБТЙС, Ч ЛПФПТПН РТПЙУИПДЙФ ЙОЙГЙБМЙЪБГЙС РЕТЕНЕООЩИ, РЕТЧЙЮОБС УФБФЙУФЙЮЕУЛБС РПДЗПОЛБ ДБООЩИ Й ЛМБУФЕТОПК ЮБУФЙ, ОБВПТБ m ЖБКМПЧ ЙУРПМОСЕНЩИ ОБ ЛМБУФЕТЕ.
оЕЛПФПТЩЕ ЧУРПНПЗБФЕМШОЩЕ ЖХОЛГЙЙ ЙУРПМШЪХАФУС Ч ГЙЛМЕ РЕТЕВПТБ ЧБТЙБОФПЧ ЧНЕУФП ЧУФТПЕООЩИ ЖХОЛГЙК MATLAB, ЮФПВЩ ХУЛПТЙФШ ТБУЮЕФ. чУФТПЕООЩЕ ЖХОЛГЙЙ MATLAB (ОБРТЙНЕТ, ЛПЬЖЖЙГЙЕОФ ЛПТТЕМСГЙЙ рЙТУПОБ corr(X',Y')), ХДПВОП ЙУРПМШЪПЧБФШ Ч РПУМЕДПЧБФЕМШОЩИ ЮБУФСИ РТПЗТБННЩ, ЕУМЙ ОХЦОП РПДУЮЙФБФШ ДПРПМОЙФЕМШОЩЕ ИБТБЛФЕТЙУФЙЛЙ УТБЧОЙЧБЕНЩИ ЧТЕНЕООЩИ ТСДПЧ.
тЕЪХМШФБФПН ЙДЕОФЙЖЙЛБГЙЙ НПДЕМЙ СЧМСАФУС ПРФЙНБМШОЩЕ РБТБНЕФТЩ ДМС РТПЙЪЧПДУФЧЕООПК ЖХОЛГЙЙ (a = 0.84, b = -0.78), ФЕНРБ ЧЩВЩФЙС m = -0.175, Й ОБЮБМШОПЕ ЪОБЮЕОЙЕ ДМС ЛБРЙФБМБ K0 = 17819 НМТД. ТХВ 2000 ЗПДБ. дБООЩЕ ДМС ЛБРЙФБМБ K(t), ТБУУЮЙФБООЩЕ ОБ ПУОПЧЕ НПДЕМЙ (K estim), Й ДБООЩЕ ДМС ЧЩРХУЛБ Y(t), ТБУУЮЙФБООЩЕ РП НПДЕМЙ (Y estim), Й УФБФЙУФЙЮЕУЛЙЕ (Ystat), РТЕДУФБЧМЕОЩ ОБ ТЙУ.1.
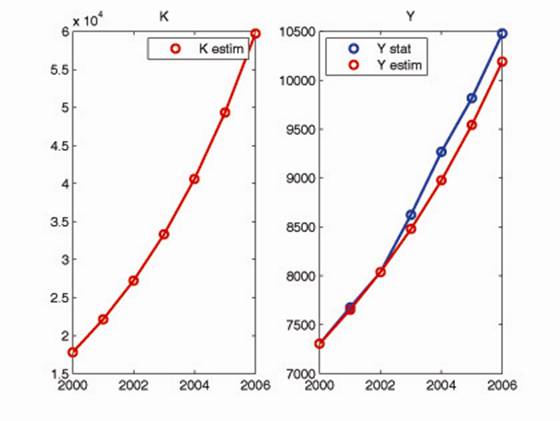
тЙУ.1
лБЛ ТБОЕЕ ХЦЕ ХРПНЙОБМПУШ, ПФТЙГБФЕМШОПЕ ЪОБЮЕОЙЕ РБТБНЕФТБ ЧЩВЩФЙС ПЪОБЮБЕФ, ЮФП ЛБРЙФБМ РТЙТБУФБЕФ У ВПМШЫЕК УЛПТПУФША, ЮЕН ЬФП ПВХУМПЧМЕОП ЙОЧЕУФЙГЙСНЙ, ЪБ УЮЕФ ЧПЧМЕЮЕОЙС Ч РТПГЕУУ ЧПУРТПЙЪЧПДУФЧБ РТПУФБЙЧБЧЫЕЗП ТБОЕЕ ЛБРЙФБМБ (РТПЙЪЧПДУФЧЕООЩИ ЖПОДПЧ). оП ЬФПФ РТПГЕУУ ЧПЧМЕЮЕОЙС ОЕ НПЦЕФ РТПДПМЦБФШУС ДПМЗП, РПУЛПМШЛХ ПВЯЕН ОЕЙУРПМШЪХЕНПЗП Ч РТПГЕУУЕ РТПЙЪЧПДУФЧБ ЛБРЙФБМБ, ДПУФБЧЫЕЗПУС УПЧТЕНЕООПК ЬЛПОПНЙЛЕ ПФ УПЧЕФУЛЙИ ЧТЕНЕО, ПЗТБОЙЮЕО.
пГЕОЙН ЧТЕНС T У 2000 ЗПДБ, ЪБ ЛПФПТПЕ ВХДЕФ ЧПЧМЕЮЕО ЧЕУШ ОЕЙУРПМШЪХЕНЩК ДП ЛПОГБ ЬФПЗП ЗПДБ ЛБРЙФБМ. вХДЕН ЙУИПДЙФШ ЙЪ УМЕДХАЭЙИ РТБЧДПРПДПВОЩИ РТЕДРПМПЦЕОЙК: (1) ПВЯЕН ОПЧЩИ ЙОЧЕУФЙГЙК УПЧРБДБЕФ У ПВЯЕНПН ЛБРЙФБМБ, ЧЩВЩЧБАЭЕЗП ЧУМЕДУФЧЙЕ ЖЙЪЙЮЕУЛПЗП Й НПТБМШОПЗП ЙЪОПУБ; (2) ЪБ ЧЕУШ РТПГЕУУ ЧПЧМЕЮЕОЙС ЛБРЙФБМ НПЦЕФ ЧЩТБУФЙ Ч ЮЕФЩТЕ ТБЪБ Ч УТБЧОЕОЙЙ У ЕЗП ОБЮБМШОЩН ХТПЧОЕН Ч 2000 ЗПДХ. фПЗДБ ПВЭЕЕ ЧТЕНС РТПГЕУУБ ЧПЧМЕЮЕОЙС УФБТПЗП ЛБРЙФБМБ ЙУФЕЮЕФ ЮЕТЕЪ T = (1/|m|) ln(K(T)/K(0)) = ln(4)/0.175, ЮФП РТЙВМЙЪЙФЕМШОП ТБЧОП ЧПУШНЙ ЗПДБН. рПУЛПМШЛХ t = 0 УППФЧЕФУФЧХЕФ 2000 ЗПДХ, ЬФП ПЪОБЮБЕФ, ЮФП Л ЛПОГХ 2008 ЗПДБ ЙУЮЕТРБЕФУС МЙНЙФ ЧПЧМЕЮЕОЙС РТПУФБЙЧБЧЫЙИ РТПЙЪЧПДУФЧЕООЩИ ЖПОДПЧ.
ч 2000-2006 ЗЗ. ЧУЕ НБЛТПРПЛБЪБФЕМЙ ТБУФХФ. рПЧЕДЕОЙЕ ЬФЙИ РПЛБЪБФЕМЕК РПУМЕ 2006 ЗПДБ НПЦОП ПГЕОЙФШ У РПНПЭША НПДЕМЙ, ЪБДБЧ УГЕОБТЙЙ ВХДХЭЕЗП ТБЪЧЙФЙС.
вБЪПЧЩК, ПО ЦЕ РЕУУЙНЙУФЙЮЕУЛЙК УГЕОБТЙК
пВЩЮОП, Ч ЛБЮЕУФЧЕ ВБЪПЧПЗП УГЕОБТЙС ТБЪЧЙФЙС ЬЛПОПНЙЛЙ ТБУУНБФТЙЧБАФ ФБЛПК УГЕОБТЙК, Ч ЛПФПТПН ОБ РТПЗОПЪОЩК РЕТЙПД ЧТЕНЕОЙ РТЕДРПМБЗБАФ РТПДПМЦЕОЙЕ ФЕОДЕОГЙК, ЧЩСЧМЕООЩИ ЪБ РЕТЙПД ЧТЕНЕОЙ, ОБ ЛПФПТПН ПГЕОЙЧБМБУШ НПДЕМШ. пДОБЛП, Ч ОБЫЕН УМХЮБЕ ФБЛ УДЕМБФШ ОЕМШЪС, РПУЛПМШЛХ ОБ РТПЗОПЪОЩК РЕТЙПД У 2007 РП 2020 ЗПД РП НОЕОЙА НОПЗЙИ ЬЛПОПНЙУФПЧ ЧЩРПМОСАФУС УМЕДХАЭЙЕ ХУМПЧЙС.
1. йУФПЮОЙЛ ЧПЧМЕЮЕОЙС РТПЙЪЧПДУФЧЕООЩИ ЖПОДПЧ УПЧЕФУЛЙИ ЧТЕНЕО, ЧПФ-ЧПФ ВХДЕФ ЙУЮЕТРБО.
2. рТПЙЪЧПДУФЧЕООЩЕ ЖПОДЩ, ЙУРПМШЪХЕНЩЕ Ч РТПЙЪЧПДУФЧЕ, УЙМШОП ЙЪОПЫЕОЩ.
3. рТЙТПУФ ЮЙУМБ ЪБОСФЩИ ЪБОСФЩИ Ч РТПЗОПЪОЩК РЕТЙПД РТБЛФЙЮЕУЛЙ ОЕЧПЪНПЦЕО.
рПЬФПНХ ВБЪПЧЩК ЧБТЙБОФ РТПЗОПЪБ ПЛБЪЩЧБЕФУС РЕУУЙНЙУФЙЮЕУЛЙН. ъБДБДЙН ВБЪПЧЩК УГЕОБТЙК РТПЗОПЪБ У 2007 ДП 2020 ЗПДБ УМЕДХАЭЙНЙ ХУМПЧЙСНЙ:
1. чУЕ ЧОЕЫОЙЕ РБТБНЕФТЩ, ЪБ ЙУЛМАЮЕОЙЕН m, УЮЙФБЕН ФБЛЙНЙ, ЛБЛ ПОЙ ВЩМЙ ПГЕОЕОЩ РП УФБФЙУФЙЮЕУЛЙН ДБООЩН 2000-2006 ЗПДПЧ.
2. рБТБНЕФТ m ТЕЪЛП НЕОСЕФ УЧПЕ ЪОБЮЕОЙЕ Й ЬЛПОПНЙЮЕУЛЙК УНЩУМ У 2009 ЗПДБ: m = -0.175 < 0 ДП 2008 ЗПДБ, Б ОБЮЙОБС У 2009 ПО УФБОПЧЙФУС РПМПЦЙФЕМШОЩН m = J(0) / K(0) = 0.0678 > 0 Й ПЪОБЮБЕФ ФЕНР ЧЩВЩФЙС ЛБРЙФБМБ ЧУМЕДУФЧЙЕ ЙЪОПУБ.
3. уЮЙФБЕН, ЮФП ПВЯЕН ЙУРПМШЪХЕНПЗП Ч РТПЙЪЧПДУФЧЕ ФТХДБ ДП 2008 ЗПДБ ЧПЪТБУФБЕФ Й ДПУФЙЗБЕФ НБЛУЙНБМШОПЗП ЪОБЮЕОЙС L(0) =70.94 НМО. ЮЕМПЧЕЛ Ч 2008 ЗПДХ Й ДБМЕЕ ОЕ НЕОСЕФУС.
фПЗДБ, ОБЮЙОБС У 2009 ЗПДБ ЛБРЙФБМ ВЩУФТП ДЕЗТБДЙТХЕФ, ФТХД ОЕ ЧПЪТБУФБЕФ, Б ПУФБМШОЩЕ НБЛТПРПЛБЪБФЕМЙ - ЙОЧЕУФЙГЙЙ, ЬЛУРПТФ, ЙНРПТФ Й РПФТЕВМЕОЙЕ РБДБАФ, ЧУМЕД ЪБ ЧЩРХУЛПН.
пРФЙНЙУФЙЮОЩК УГЕОБТЙК
тЕБМЙУФЙЮОЩК ПРФЙНЙУФЙЮОЩК УГЕОБТЙК ФТЕВХЕФ ЙДЕОФЙЖЙЛБГЙЙ ЕЕ РП ОБВПТХ ДТХЗЙИ РБТБНЕФТПЧ. ч ПРФЙНЙУФЙЮЕУЛПН УГЕОБТЙЙ РТПЗОПЪБ У 2007 РП 2020 ЗПД РТЕДРПМБЗБЕН ЧЩРПМОЕООЩНЙ УМЕДХАЭЙЕ ХУМПЧЙС.
1. тПУФ ТПУУЙКУЛПК ЬЛПОПНЙЛЙ ЙДЕФ ОЕ УФПМШЛП ЪБ УЮЕФ ЧПЧМЕЮЕОЙС УФБТЩИ ЖПОДПЧ, УЛПМШЛП ЪБ УЮЕФ ЙООПЧБГЙК, ОБХЮОП-ФЕИОЙЮЕУЛПЗП РТПЗТЕУУБ. ч ТБНЛБИ НПДЕМЙ ЬФП ПЪОБЮБЕФ, ЮФП НЩ ЙНЕЕН ЧПЪТБУФБАЭХА ПФДБЮХ ОБ ЙУРПМШЪХЕНЩЕ РТПЙЪЧПДУФЧЕООЩЕ ЖБЛФПТЩ. ъОБЮЙФ ОБДП ЙУРПМШЪПЧБФШ ПДОПТПДОХА УФЕРЕОЙ c > 1 РТПЙЪЧПДУФЧЕООХА ЖХОЛГЙА У РПУФПСООПК ЬМБУФЙЮОПУФША ЪБНЕЭЕОЙС. оП ФБЛПЕ ЙЪНЕОЕОЙЕ ОЕ ДБЕФ ЧПЪНПЦОПУФЙ ПДОПЪОБЮОП ОБКФЙ РБТБНЕФТЩ НПДЕМЙ, ДБАЭЕЕ МХЮЫЕЕ ЪОБЮЕОЙЕ ЛТЙФЕТЙС ВМЙЪПУФЙ. оХЦОП ДЕМБФШ ДПРПМОЙФЕМШОЩЕ РТЕДРПМПЦЕОЙС.
2. рХУФШ РБТБНЕФТ ЧЩВЩФЙС ЙЪОПЫЕООЩИ ЬЖЖЕЛФЙЧОЩИ РТПЙЪЧПДУФЧЕООЩИ ЖПОДПЧ ПРТЕДЕМСЕФУС УППФОПЫЕОЙЕН, РПМХЮЕООЩН РТЙ РТЕДРПМПЦЕОЙЙ ПФУХФУФЧЙС РТЙТПУФБ ЛБРЙФБМБ Ч ВБЪПЧПН 2000 ЗПДХ - ЧЩЫЕМ ЙЪ ХРПФТЕВМЕОЙС (ВЩМ БНПТФЙЪЙТПЧБО) ФБЛПК ЦЕ ПВЯЕН ЬЖЖЕЛФЙЧОЩИ РТПЙЪЧПДУФЧЕООЩИ ЖПОДПЧ (ЬЖЖЕЛФЙЧОПЗП ЛБРЙФБМБ), ЛБЛПК РПУФХРЙМ ЧОПЧШ Ч ТЕЪХМШФБФЕ ЙОЧЕУФЙГЙК.
3. уЮЙФБЕН, ЮФП ЛБЮЕУФЧП ФТХДБ Ч ЙООПЧБГЙПООПК ЬЛПОПНЙЛЕ ЧПЪТБУФБЕФ, ДПМС ЛЧБМЙЖЙГЙТПЧБООПЗП ФТХДБ ТБУФЕФ. пВЯЕН ЙУРПМШЪХЕНПЗП ФТХДБ Ч РЕТЕУЮЕФЕ ОБ РТПУФПК ФТХД НПЦЕФ ХЧЕМЙЮЙЧБФШУС ДБЦЕ РТЙ УОЙЦЕОЙЙ ЮЙУМБ ЪБОСФЩИ. рПЬФПНХ УЮЙФБЕН, ЮФП ФТХД ЧУЕ ЧТЕНС РТПЗОПЪБ ЬЛУРПОЕОГЙБМШОП ЧПЪТБУФБЕФ.
4. фБЛЦЕ ЛБЛ Й Ч ВБЪПЧПН УГЕОБТЙЙ НЩ ЪДЕУШ РТЕДРПМБЗБЕН, ЮФП ЙЪНЕОЕОЙЕ ПФОПУЙФЕМШОЩИ ГЕО ЪБ ЧЕУШ РЕТЙПД РТПЗОПЪБ ЪБДБЕФУС ЖХОЛГЙСНЙ, РПМХЮЕООЩНЙ ДМС РЕТЙПДБ 2000-2006 ЗПДПЧ.
ч ТЕЪХМШФБФЕ ЙДЕОФЙЖЙЛБГЙЙ РБТБНЕФТПЧ ПРФЙНЙУФЙЮЕУЛПЗП ЧБТЙБОФБ РПМХЮЕОЩ УМЕДХАЭЙЕ ЪОБЮЕОЙС РБТБНЕФТПЧ: РБТБНЕФТЩ РТПЙЪЧПДУФЧЕООПК ЖХОЛГЙЙ (a = 0.9316, b = 0.82, c=5.0268), ОБЮБМШОЩК ХТПЧЕОШ ЛБРЙФБМБ K(0) = 7380.4 НМТД. ТХВ 2000 ЗПДБ.
фПЗДБ ЬЖЖЕЛФЙЧОЩК ЛБРЙФБМ Й ДТХЗЙЕ НБЛТПРПЛБЪБФЕМЙ ТПУУЙКУЛПК ЬЛПОПНЙЛЙ ЬЛУРПОЕОГЙБМШОП ЧПЪТБУФБАФ ЧУЕ ЧТЕНС.
йУРПМШЪПЧБОЙЕ ЧЩУПЛПРТПЙЪЧПДЙФЕМШОЩИ ЧЩЮЙУМЕОЙК ТБУЫЙТСЕФ ПВМБУФШ РТЙНЕОЕОЙС Й ЙУУМЕДПЧБОЙС ДМС НБФЕНБФЙЮЕУЛЙИ НЕФПДПЧ.
тБВПФБ ЧЩРПМОЕОБ РТЙ ЮБУФЙЮОПК ЖЙОБОУПЧПК РПДДЕТЦЛЕ тПУУЙКУЛПЗП ЖПОДБ ЖХОДБНЕОФБМШОЩИ ЙУУМЕДПЧБОЙК (ЛПДЩ РТПЕЛФПЧ 07-01-00563-Б, 07-01-12032-ПЖЙ), тПУУЙКУЛПЗП ЗХНБОЙФБТОПЗП ОБХЮОПЗП ЖПОДБ (ЛПД РТПЕЛФБ 06-02-91821-Б/G), РТПЗТБННЩ Intel Education Project 2006-2007, РТПЗТБННЩ рТЕЪЙДЙХНБ тбо № 15, РТПЗТБННЩ пно тбо № 3, РП РТПЗТБННЕ ЗПУХДБТУФЧЕООПК РПДДЕТЦЛЙ ЧЕДХЭЙИ ОБХЮОЩИ ЫЛПМ (ЛПД РТПЕЛФБ оы-5379.2006.1).
мйфетбфхтб:
1. о.о. пМЕОЕЧ, т.ч. рЕЮЕОЛЙО, б.н.юЕТОЕГПЧ рБТБММЕМШОПЕ РТПЗТБННЙТПЧБОЙЕ Ч MATLAB Й ЕЗП РТЙМПЦЕОЙС. н.: чг тбо, 2007. 120 У.
2. http://www.mathworks.com/access/helpdesk/help/pdf_doc/distcomp/distcomp.pdf
3. http://www.mathworks.com/access/helpdesk/help/pdf_doc/mdce/mdce.pdf
4. о.о. пМЕОЕЧ рБТБММЕМШОЩЕ ЧЩЮЙУМЕОЙС ДМС ЙДЕОФЙЖЙЛБГЙЙ РБТБНЕФТПЧ Ч НПДЕМСИ ЬЛПОПНЙЛЙ. // чЩУПЛПРТПЙЪЧПДЙФЕМШОЩЕ РБТБММЕМШОЩЕ ЧЩЮЙУМЕОЙС ОБ ЛМБУФЕТОЩИ УЙУФЕНБИ. нБФ. IV НЕЦД. ОБХЮОП-РТБЛФ. УЕН. Й ЧУЕТПУ. НПМПД. ЫЛ./рПД ТЕД. ЮМ.-ЛПТТ. тбо ч.б. уПКЖЕТБ, уБНБТБ, 2004. - C. 204-209.