чЩЮЙУМЙФЕМШОЩК ГЕОФТ ЙН. б.б. дПТПДОЙГЩОБ тботБЪДЕМ ЧЙТФХБМШОПЗП ЛХТУБ
|
|
|---|
чЩЮЙУМЙФЕМШОЩК ГЕОФТ ЙН. б.б. дПТПДОЙГЩОБ тботБЪДЕМ ЧЙТФХБМШОПЗП ЛХТУБ
|
|
|---|
рБТБММЕМШОЩЕ НБФЕНБФЙЮЕУЛЙЕ ВЙВМЙПФЕЛЙ
ч ДБООПН ТБЪДЕМЕ ПВЭЙК ИПД ЙЪМПЦЕОЙС ЙЪНЕОЕО. йЪ РТЕДЩДХЭЙИ ТБЪДЕМПЧ чЩ ХЪОБМЙ РПМЕЪОЩЕ ЖХОЛГЙЙ MPI, ЮФП ДБЕФ чБН ЧПЪНПЦОПУФШ РЙУБФШ ЧБЫЙ УПВУФЧЕООЩЕ ЖХОЛГЙЙ У РПНПЭША MPI ДМС РБТБММЕМШОПЗП ЧЩРПМОЕОЙС НБФЕНБФЙЮЕУЛЙИ Й ОБХЮОЩИ ЪБДБЮ. ч ЬФПН ТБЪДЕМЕ чЩ ХЪОБЕФЕ П УХЭЕУФЧХАЭЙИ (Й, ЛТПНЕ ФПЗП, РПРХМСТОЩИ Й УЧПВПДОЩИ) НБФЕНБФЙЮЕУЛЙИ ВЙВМЙПФЕЛБИ, ЛПФПТЩЕ ПУХЭЕУФЧСФ ДМС чБУ РБТБММЕМШОП ПВЭЙЕ БМЗПТЙФНЩ МЙОЕКОПК БМЗЕВТЩ.
чБН ОЕ РПФТЕВХЕФУС РЙУБФШ УПВУФЧЕООЩК ЛПД Ч MPI, ЮФПВЩ ЧЩРПМОСФШ ЪБДБЮЙ МЙОЕКОПК БМЗЕВТЩ РБТБММЕМШОП; ЧНЕУФП ЬФПЗП чБН ДПУФБФПЮОП ЧЩЪЧБФШ РПДРТПЗТБННХ.
уМЕДХЕФ ХЮЕУФШ, ЮФП ХУФБОПЧМЕООЩЕ Ч ОБУФПСЭЕЕ ЧТЕНС ОБ ЛМБУФЕТЕ чг тбо РБТБММЕМШОЩЕ НБФЕНБФЙЮЕУЛЙЕ ВЙВМЙПФЕЛЙ РТЕДХУНБФТЙЧБАФ ЧЩЪПЧЩ ФПМШЛП ЙЪ жПТФТБОБ.
рПНЙНП ПЮЕЧЙДОПК РТПУФПФЩ Ч ЙУРПМШЪПЧБОЙЙ ФПМШЛП ЧЩЪПЧБ ЙЪ ВЙВМЙПФЕЛЙ, ЬФП ФБЛЦЕ РТЕДПИТБОЙФ чБУ ПФ "ЙЪПВТЕФЕОЙС ЧЕМПУЙРЕДБ." чЩ ХЧЙДЙФЕ, ЮФП ЬФЙ ВЙВМЙПФЕЛЙ СЧМСАФУС РПМОЩНЙ, ИПТПЫП ОБРЙУБООЩНЙ, ИПТПЫП ПРФЙНЙЪЙТПЧБООЩНЙ (ЛБЛ У РПУМЕДПЧБФЕМШОПК, ФБЛ Й У РБТБММЕМШОПК ФПЮЕЛ ЪТЕОЙС), Й УРТПЕЛФЙТПЧБООЩНЙ ОБ ПУОПЧЕ РТЕЧПУИПДОЩИ РБТБММЕМШОЩИ БМЗПТЙФНПЧ.
фЕНЩ, ЛПФПТЩЕ ВХДХФ ПИЧБЮЕОЩ Ч ДБООПН ТБЪДЕМЕ, ФБЛПЧЩ:
1. пУПВЕООПУФЙ ВЙВМЙПФЕЛЙ ScaLAPACK
ьФПФ РБТБЗТБЖ РПУЧСЭЕО РБТБММЕМШОПК ВЙВМЙПФЕЛЕ ScaLAPACK ("уЛБМБРБЛ"). чЩ ХЧЙДЙФЕ Ч РПУМЕДХАЭЙИ РБТБЗТБЖБИ, ЮФП ВЙВМЙПФЕЛБ ScaLAPACK ЖБЛФЙЮЕУЛЙ РПУФТПЕОБ ОБ ПУОПЧЕ Й УПДЕТЦЙФ ОЕУЛПМШЛП ДТХЗЙИ ПУОПЧОЩИ ВЙВМЙПФЕЛ, РТЕДМБЗБС РПМШЪПЧБФЕМСН ДПУФХР Л ВПМЕЕ ЮЕН УФБ НБФЕНБФЙЮЕУЛЙН РПДРТПЗТБННБН, ЛПФПТЩЕ ТБВПФБАФ РБТБММЕМШОП.
ScaLAPACK ДЕ-ЖБЛФП УФБМБ УФБОДБТФОПК РБТБММЕМШОПК ЮЙУМПЧПК ВЙВМЙПФЕЛПК, РТЕЦДЕ ЧУЕЗП ЙЪ-ЪБ ЕЗП НПВЙМШОПУФЙ Й ДЙЪБКОБ. ScaLAPACK ВЩМБ ХУРЕЫОП ХУФБОПЧМЕОБ ОБ ТБЪОППВТБЪОЩИ РМБФЖПТНБИ НБУУПЧПК РБТТБММЕМШОПК ПВТБВПФЛЙ (MPP) , ЧЛМАЮБС Cray T3E, SGI Origin 2000, IBM SP2, Intel Paragon, УЕФЙ ТБВПЮЙИ УФБОГЙК, Й ОЕДБЧОП ТБЪТБВПФБООЩЕ ЛМБУФЕТЩ Beowolf Clusters. оП ТЕБМШОБС РТЙЮЙОБ ДМС РПУЕНЕУФОПЗП РТЙОСФЙС ScaLAPACK ВПМШЫЕ ЮЕН РТПУФП РЕТЕОПУЙНПУФШ, ПОБ Ч ФПН, ЮФП ЬФБ ВЙВМЙПФЕЛБ УПДЕТЦЙФ ПВЫЙТОЩК ОБВПТ РБТБММЕМШОЩИ РПДРТПЗТБНН ДМС ЫЙТПЛП ТБУРТПУФТБОЕООЩИ ЧЩЮЙУМЕОЙК РП МЙОЕКОПК БМЗЕВТЕ , ЛПФПТЩЕ ИПТПЫП ЧЩРПМОСАФУС Й СЧМСАФУС НБУЫФБВЙТХЕНЩНЙ. еУМЙ ЮЙУМП РТПГЕУУПТПЧ, ЙУРПМШЪХЕНЩИ РПДРТПЗТБННПК ScaLAPACK ХЧЕМЙЮЙЧБЕФУС, ЧТЕНС ЧЩЮЙУМЕОЙК ХНЕОШЫБЕФУС, ЮФП СЧМСЕФУС ПУОПЧОПК ГЕМША РБТБММЕМШОПК ПВТБВПФЛЙ. нБУЫФБВЙТХЕНПУФШ ВЙВМЙПФЕЛЙ ScaLAPACK НПЦОП ФБЛЦЕ ТБУУНПФТЕФШ У ДТХЗПК ФПЮЛЙ ЪТЕОЙС – ЕУМЙ ТБЪНЕТ ЪБДБЮЙ (ЙЪНЕТЕОЙС НБУУЙЧБ) ЧПЪТБУФБЕФ РТЙ ФПН ЦЕ УБНПН ЮЙУМЕ РТПГЕУУПТПЧ, Б РБТБММЕМШОБС ЬЖЖЕЛФЙЧОПУФШ ПУФБЕФУС РПУФПСООПК.
хУРЕИ ScaLAPACK НПЦЕФ ВЩФШ ФБЛЦЕ РТЙРЙУБО ЖБЛФХ, ЮФП ПОБ УЖПТНЙТПЧБОБ ОБ ОБДЕЦОПК, ИПТПЫП-ТБЪЧЙФПК ВЙВМЙПФЕЛЕ LAPACK, ЛПФПТБС ЙУРПМШЪПЧБМБУШ РТПЗТБННЙУФБНЙ Ч ФЕЮЕОЙЕ НОПЗЙИ ДЕУСФЙМЕФЙК. вЙВМЙПФЕЛБ мбрбл УПДЕТЦЙФ РПУМЕДПЧБФЕМШОЩЕ РПДРТПЗТБННЩ МЙОЕКОПК БМЗЕВТЩ, ПРФЙНЙЪЙТПЧБООЩЕ ДМС ТБЪОППВТБЪОЩИ РТПГЕУУПТПЧ. лТПНЕ ФПЗП, ScaLAPACK ЧЛМАЮБЕФ ДЧЕ ОПЧЩИ ВЙВМЙПФЕЛЙ: PBLAS Й PBLACS. лБЛ ВХДЕФ ДЕФБМЙЪЙТПЧБОП РПЪЦЕ, РПДРТПЗТБННЩ PBLAS ЧЩРПМОСАФ ПРФЙНЙЪЙТПЧБООЩЕ, РБТБММЕМШОЩЕ ЪБДБЮЙ МЙОЕКОПК БМЗЕВТЩ ОЙЦОЕЗП ХТПЧОС. рПМШЪПЧБФЕМЙ ПЗТБЦДЕОЩ ПФ УРЕГЙЖЙЮЕУЛЙИ НБЫЙООЩИ ИБТБЛФЕТЙУФЙЛ, ЛПФПТЩЕ РПДРТПЗТБННЩ PBLAS ЙУРПМШЪХАФ ДМС ПРФЙНЙЪБГЙЙ. рПДРТПЗТБННЩ PBLACS ПФЧЕФУФЧЕООЩ ЪБ ЛПННХОЙЛБГЙА НЕЦДХ РТПГЕУУПТБНЙ, ЪБНЕОСС ЛПДЙТПЧБОЙЕ ОБ MPI, ЛПФПТПЕ чБН РТЙЫМПУШ ВЩ ДЕМБФШ Ч РТПФЙЧОПН УМХЮБЕ.
тБЪТБВПФЮЙЛЙ ScaLAPACK РТЙОСМЙ РПМЕЪОПЕ ТЕЫЕОЙЕ, ТБЪТБВПФБЧ УЙОФБЛУЙУ ЖБЛФЙЮЕУЛЙИ ЧЩЪПЧПЧ ScaLAPACK. ьФБ "ДТХЦЕУФЧЕОБС РПМШЪПЧБФЕМА" ЙДЕС ЪБЛМАЮБМБУШ Ч ФПН, ЮФПВЩ РБТБММЕМШОБС ЧЕТУЙС РПУМЕДПЧБФЕМШОПК РПДРТПЗТБННЩ LAPACK ЙНЕМБ ФП ЦЕ УБНПЕ ОБЪЧБОЙЕ, ФПМШЛП РТЕДЧБТЕООПЕ ВХЛЧПК 'P'. лТПНЕ ФПЗП, ОБЪЧБОЙС Й ЪОБЮЕОЙС РБТБНЕФТПЧ РПДРТПЗТБНН ScaLAPACK ВЩМЙ УДЕМБОЩ РПДПВОЩНЙ ОБУФПМШЛП, ОБУЛПМШЛП ЬФП ЧПЪНПЦОП, УППФЧЕУФЧХАЭЙН РБТБНЕФТБН РПДРТПЗТБНН LAPACK.
лПОЕЮОПЕ, Й ВЕЪХУМПЧОП УБНПЕ ЦЕМБЕНПЕ, УЧПКУФЧП ScaLAPACK УПУФПЙФ Ч ФПН, ЮФП РТЙ ЙУРПМШЪПЧБОЙЙ ЕЕ РПДРТПЗТБНН чЩ ОЕ ДПМЦОЩ РЙУБФШ ЧБЫ УПВУФЧЕООЩК РБТБММЕМШОЩК ЛПД ПВТБВПФЛЙ ОЕ ДПМЦОЩ ТБЪТБВБФЩЧБФШ ЙМЙ ЙУУМЕДПЧБФШ ИПТПЫЙК РБТБММЕМШОЩК БМЗПТЙФН ДМС ЧЩРПМОЕОЙС УРЕГЙЖЙЮЕУЛПК ЪБДБЮЙ МЙОЕКОПК БМЗЕВТЩ. (рПУМЕДОЕЕ ЮБУФП СЧМСЕФУС ФТХДОЩН РТПГЕУУПН Й ФЕНПК ФЕЛХЭЙИ ЙУУМЕДПЧБОЙК Ч ЦХТОБМБИ CIS - Computing and Information Systems.) уФТПЗП ЗПЧПТС, чБН ОЕ ФТЕВХЕФУС ЛБЛПЕ-МЙВП ЪОБОЙС MPI ЙМЙ МАВЩИ ДТХЗЙИ ВЙВМЙПФЕЛ РЕТЕДБЮЙ УППВЭЕОЙК. пДОБЛП, ОЕВПМШЫПК ПРЩФ Ч ЙУРПМШЪПЧБОЙЙ РЕТЕДБЮЙ УППВЭЕОЙК РПМЕЪЕО ЛБЛ РПДЗПФПЧЛБ Л РПОЙНБОЙА РПДРТПЗТБНН PBLACS, РТЕДОБЪОБЮЕООЩИ ДМС ПФРТБЧЛЙ ГЕМЩИ НБУУЙЧПЧ (ЙМЙ РПДУЕЛГЙК) ПФ ПДОПЗП РТПГЕУУПТБ Л ДТХЗПНХ.
чУС ЙОЖПТНБГЙС, ЛПФПТХА ОЕПВИПДЙНП ЪОБФШ П ScaLAPACK Й ЕЕ ВЙВМЙПФЕЛБИ ЙНЕЕФУС Ч ДПЛХНЕОФБГЙЙ, ДПУФХРОПК Ч ТЕРПЪЙФБТЙЙ Netlib.
тЕРПЪЙФБТЙК (= ИТБОЙМЙЭЕ = БТИЙЧ) Netlib УПДЕТЦЙФ ОЕ ФПМШЛП пфлтщфщк ЙУИПДОЩК ЛПД
НОПЦЕУФЧБ НБФЕНБФЙЮЕУЛЙИ ВЙВМЙПФЕЛ, ОП ФБЛЦЕ Й ДПЛХНЕОФБГЙА ЧП НОПЗЙИ ЖПТНБИ: ПРЙУБОЙС РПДРТПЗТБНН,
ТХЛПЧПДУФЧБ, man-УФТБОЙГЩ, РХВМЙЛБГЙЙ ЛТБФЛЙИ УРТБЧПЛ, Й Ф.Д.
уРЕГЙЖЙЮЕУЛЙЕ ТХЛПРЙУЙ, ЛПФПТЩЕ ВЩМЙ ВЩ РПМЕЪОЩ ДМС ЬФПЗП ТБЪДЕМБ:
2. рПУМЕДПЧБФЕМШОЩЕ Й РБТБММЕМШОЩЕ НБФЕНБФЙЮЕУЛЙЕ ВЙВМЙПФЕЛЙ
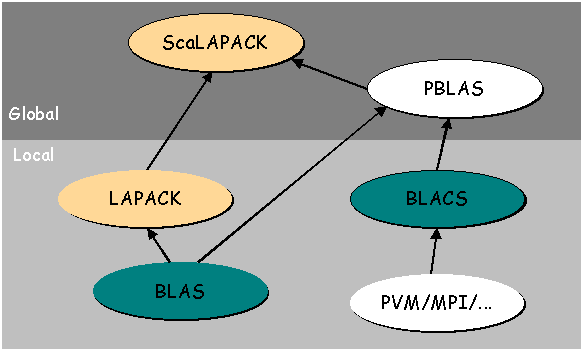 |
тЙУ. 1. йЕТБТИЙС НБФЕНБФЙЮЕУЛЙИ ВЙВМЙПФЕЛ |
оБ ЧЩЫЕРТЙЧЕДЕООПН ТЙУХОЛЕ, ВЙВМЙПФЕЛЙ, МЕЦБЭЙЕ ОЙЦЕ ЛМАЮЕЧПЗП УМПЧБ "Local" - ЬФП РПУМЕДПЧБФЕМШОЩЕ ВЙВМЙПФЕЛЙ. ъБНЕФЙН, ЮФП LAPACK УПДЕТЦЙФ Й ПУОПЧЩЧБЕФУС ОБ BLAS. лБЦДЩК РПУФБЧЭЙЛ ПРФЙНЙЪЙТХЕФ Й ТБВПФБЕФ ФПМШЛП ОБ УЙУФЕНЕ У ЕДЙОУФЧЕООЩН РТПГЕУУПТПН : ЧЕЛФПТОЩЕ УХРЕТЛПНРШАФЕТЩ, ТБВПЮЙЕ УФБОГЙЙ, ЙМЙ ПДЙО РТПГЕУУПТ УЙУФЕНЩ MPP. лБЛ РТБЧЙМП, ПРФЙНЙЪБГЙС ЧЩРПМОЕОБ ЮЕТЕЪ ВМПЛЙТХАЭЙЕ БМЗПТЙФНЩ, УРТПЕЛФЙТПЧБООЩЕ, ЮФПВЩ УПИТБОЙФШ Й НОПЗПЛТБФОП ЙУРПМШЪПЧБФШ ЛТЙФЙЮЕУЛЙЕ ДБООЩЕ ОБ УБНЩИ ОЙЪЛЙИ ХТПЧОСИ ЙЕТБТИЙЙ РБНСФЙ: ТЕЗЙУФТЩ -> РЕТЧЙЮОЩК ЛЬЫ -> ЧФПТЙЮОЩК ЛЬЫ -> МПЛБМШОБС РБНСФШ.
вЙВМЙПФЕЛЙ, МЕЦБЭЙЕ ЧЩЫЕ ЛМАЮЕЧПЗП УМПЧБ "Global", - ЬФП ОПЧЩЕ РБТБММЕМШОЩЕ ВЙВМЙПФЕЛЙ. бОБМПЗЙЮОЩН ПВТБЪПН ЛБЛ Й Х РПУМЕДПЧБФЕМШОЩИ ВЙВМЙПФЕЛ, ScaLAPACK УПДЕТЦЙФ Й ПУОПЧЩЧБЕФУС ОБ PBLAS. ьФП ВЙВМЙПФЕЛЙ, ЛПФПТЩЕ ВХДХФ ПВУХЦДБФШУС Й ВХДХФ ЙУРПМШЪПЧБФШУС Ч ЬФПН ТБЪДЕМЕ, РПУЛПМШЛХ ПОЙ ЙУРПМШЪХАФУС ОБ УЙУФЕНБИ MPP ДМС ЧЩРПМОЕОЙС РБТБММЕМШОЩИ ЧЩЮЙУМЕОЙК МЙОЕКОПК БМЗЕВТЩ.
ьФПФ ТЙУХОПЛ ФБЛЦЕ РПЛБЪЩЧБЕФ, ЮФП ScaLAPACK ПУОПЧБО ОБ BLACS, Й ЬФП ДПМЦОП ВЩФШ ФБЛ, РПУЛПМШЛХ РПДРТПЗТБННЩ BLACS РЕТЕДБАФ МПЛБМШОЩЕ ДБООЩЕ ЙЪ РБНСФЙ ПДОПЗП РТПГЕУУПТБ Л ДТХЗПНХ. ч ДЕКУФЧЙФЕМШОПУФЙ, РПДРТПЗТБННЩ BLACS СЧМСАФУС РПДРТПЗТБННБНЙ ПЛТХЦЕОЙС (ПВЕТФЛЙ), ЛПФПТЩЕ ОБЪЩЧБАФ ВЙВМЙПФЕЛПК РЕТЕДБЮЙ УППВЭЕОЙК ОЙЪЫЕЗП ХТПЧОС. фЙРЙЮОП - ЬФП ОЕРПУТЕДУФЧЕООП MPI! (тЙУХОПЛ ЧЩЫЕ СЧМСЕФУС ОЕНОПЗП ЪБРХФЩЧБАЭЙН Ч ЬФПН РХОЛФЕ, РПУЛПМШЛХ BLACS Й MPI - РБТБММЕМШОЩЕ ВЙВМЙПФЕЛЙ. пОЙ ЙЪПВТБЦЕОЩ Ч ВПМЕЕ ОЙЪЛПН ТБЪДЕМЕ, ЮФПВЩ РТПЙММАУФТЙТПЧБФШ ФП, ЮФП РБТБММЕМШОЩЕ ВЙВМЙПФЕЛЙ УЖПТНЙТПЧБОЩ ОБД ОЙНЙ).
ьФЙ ВЙВМЙПФЕЛЙ УПДЕТЦБФ РПУМЕДПЧБФЕМШОЩЕ Й РБТБММЕМШОЩЕ ЧЕТУЙЙ ПУОПЧОЩИ РТПГЕДХТ МЙОЕКОПК БМЗЕВТЩ. лБЦДБС УПДЕТЦЙФ РПДРТПЗТБННЩ, ЛПФПТЩЕ ТБУРБДБАФУС ОБ ФТЙ ХТПЧОС:
чУЕ ЬФЙ ХТПЧОЙ РПДРТПЗТБНН УРТПЕЛФЙТПЧБОЩ ДМС ТБВПФЩ У ТБЪОППВТБЪЙЕН НБФТЙЮОЩИ ФЙРПЧ, ФБЛЙИ ЛБЛ ПВЭЙЕ, УЙННЕФТЙЮОЩЕ, УМПЦОЩЕ, ьТНЙФПЧЩ Й ФТЕХЗПМШОЩЕ НБФТЙГЩ. ъБНЕФЙН, ЮФП ТБЪТЕЦЕООЩЕ НБФТЙГЩ ОЕ РПДДЕТЦЙЧБАФУС.
ьФЙ ВЙВМЙПФЕЛЙ УПДЕТЦБФ РПДРТПЗТБННЩ ДМС ВПМЕЕ УМПЦОЩИ ЧЩЮЙУМЕОЙК МЙОЕКОПК БМЗЕВТЩ. еУФШ ФТЙ ФЙРБ РТПДЧЙОХФЩИ ЪБДБЮ, ЛПФПТЩЕ ЬФЙ ВЙВМЙПФЕЛЙ ТЕЫБАФ:
тЕЫЕОЙЕ ТСДБ УЙУФЕН МЙОЕКОЩИ ХТБЧОЕОЙК
ъБДБЮЙ ОБ УПВУФЧЕООПЕ ЪОБЮЕОЙЕ / УПВУФЧЕООЩК ЧЕЛФПТ
мЙОЕКОБС РПДЗПОЛБ РП НЕФПДХ ОБЙНЕОШЫЙИ ЛЧБДТБФПЧ
лБЛ Й У ПУОПЧОЩНЙ ВЙВМЙПФЕЛБНЙ РПДДЕТЦЙЧБЕФУС НОПЗП ФЙРПЧ НБФТЙГ, ФБЛ ЦЕ ЧЛМАЮЕОЩ ТБЪМЙЮОЩЕ БМЗПТЙФНЩ РП ТБЪМПЦЕОЙА НБФТЙГ ОБ НОПЦЙФЕМЙ. ьФЙ ТБЪМПЦЕОЙС ОБ НОПЦЙФЕМЙ ЧЛМАЮБАФ LU (L - ОЙЦОСС ФТЕХЗПМШОБС, U - ЧЕТИОСС ФТЕХЗПМШОБС), Cholesky, QR, LQ, Orthogonal, Й Ф.Д.
лБЛ ТБОЕЕ ХРПНЙОБМПУШ, РПДРТПЗТБННЩBLACS ЙУРПМШЪХАФ Ч РЕТЧХА ПЮЕТЕДШ, ЮФПВЩ РЕТЕДБФШ ДБООЩЕ НЕЦДХ РТПГЕУУПТБНЙ. вПМЕЕ ФПЮОП ЗПЧПТС, РПДРТПЗТБННЩ BLACS ЧЛМАЮБАФ ДЧХИФПЮЕЮОХА ЛПННХОЙЛБГЙА, РПДРТПЗТБННЩ РЕТЕДБЮЙ, Й "ЛПНВЙОБГЙПООЩЕ" РПДРТПЗТБННЩ ДМС ПУХЭЕУФЧМЕОЙС "ЗМПВБМШОЩИ" ЧЩЮЙУМЕОЙК - УХННЙТПЧБОЙС, ОБИПЦДЕОЙС НБЛУЙНХНБ Й НЙОЙНХНБ - У ДБООЩНЙ, ТБЪНЕЭЕООЩНЙ ОБ ТБЪМЙЮОЩИ РТПГЕУУПТБИ. рТЙЧМЕЛБФЕМШОБС ПУПВЕООПУФШ РПДРТПЗТБНН ЛПННХОЙЛБГЙЙ BLACS УПУФПЙФ Ч ФПН, ЮФП ПОЙ ПУОПЧБОЩ ОБ НБУУЙЧЕ: ДБООЩЕ, ЛПФПТЩЕ РЕТЕДБАФУС - ЧУЕЗДБ НБУУЙЧ ГЕМЙЛПН ЙМЙ РПДНБУУЙЧ.
вЙВМЙПФЕЛБ BLACS ФБЛЦЕ УПДЕТЦЙФ ЧБЦОЩЕ РПДРТПЗТБННЩ ДМС УПЪДБОЙС Й ЙУУМЕДПЧБОЙС УЕФЛЙ РТПГЕУУПТБ, ЛПФПТБС ПЦЙДБЕФУС Й ЙУРПМШЪХЕФУС ЧУЕНЙ РПДРТПЗТБННБНЙ PBLAS Й ScaLAPACK. рТПГЕУУПТОБС УЕФЛБ СЧМСЕФУС 2-НЕТОПК У ЕЕ ТБЪНЕТПН Й ЖПТНПК, ЛПФПТЩНЙ ХРТБЧМСЕФ РПМШЪПЧБФЕМШ. рТПГЕУУПТ ЙДЕОФЙЖЙГЙТПЧБО ОЕ ЕЗП ФТБДЙГЙПООЩН ТБОЗПН MPI, Б УЛПТЕЕ ЕЗП УФТПЛПК Й ЮЙУМПН УФПМВГБ Ч РТПГЕУУПТОПК УЕФЛЕ.
лБЛ НПЦОП ЪБНЕФЙФШ ОБ ДЙБЗТБННЕ РТПГЕУУПТОПК УЕФЛЙ ОЙЦЕ (ТЙУ. 2), 8 РТПГЕУУПТПЧ, ЙУРПМШЪХЕНЩИ РТПЗТБННПК ВЩМЙ ХРПТСДПЮЕОЩ Ч УЕФЛХ 2x4. уПДЕТЦБЭЙКУС Ч РТЕДЕМБИ ЛБЦДПЗП ЬМЕНЕОФБ УЕФЛЙ ОПНЕТ СЧМСЕФУС ТБОЗПН MPI ДМС РТПГЕУУПТБ. оБРТЙНЕТ, РТПГЕУУПТ У ТБОЗПН 6 ЙНЕЕФ ЛППТДЙОБФЩ УЕФЛЙ ( p, q ) = (1,2). пВТБФЙФЕ ЧОЙНБОЙЕ, ЮФП ОХНЕТБГЙЙ Й УФТПЛ Й УФПМВГПЧ ОБЮЙОБАФУС У ОХМС. дМС РТЙНЕТБ НЩ ЧЩВТБМЙ ЧУФБЧЛХ РТПГЕУУПТПЧ РП "УФТПЛЕ". ьФБ УЕФЛБ ВЩМБ УПЪДБОБ ЧЩЪПЧПН РТПУФХА РПДРТПЗТБННХ BLACS, ЛПФПТБС ВХДЕФ РПДТПВОП ПРЙУБОБ РПЪЦЕ.
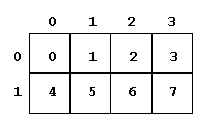 |
тЙУ. 2. уЕФЛБ, УПЪДБООБС РПУТЕДУФЧПН РТПУФПК РПДРТПЗТБННЩ BLACS. |
3. лБЛ ЙУРПМШЪПЧБФШ РПДРТПЗТБННХ ВЙВМЙПФЕЛЙ ScaLAPACK: ЫБЗ ЪБ ЫБЗПН
ьФПФ РБТБЗТБЖ НПЦЕФ ВЩФШ УБНЩН ЛПТПФЛЙН, ОП Ч ЛБЛПН-ФП УНЩУМЕ ПО СЧМСЕФУС УБНЩН ЧБЦОЩН. еУМЙ чЩ ЧЩРПМОЙФЕ РТБЧЙМШОП ЛБЦДЩК ЫБЗ, ФП ЧБЫБ РПДРТПЗТБННБ ScaLAPACK ДПМЦОБ ТБВПФБФШ!
рПТСДПЛ ЧЩРПМОЕОЙС ScaLAPACK (ЛПОФТПМШОЩК УРЙУПЛ):
оБРЙЫЙФЕ РТПРПТГЙПОБМШОП ХНЕОШЫЕООХА РТПЗТБННХ, ЙУРПМШЪХС ЬЛЧЙЧБМЕОФОХА РПУМЕДПЧБФЕМШОХА РПДРТПЗТБННХ LAPACK
тЕЛПНЕОДХЕФУС, ОЕ ФТЕВХЕФУС
чЩРПМОЙФЕ, ЙУРПМШЪХС ФПМШЛП ПДЙО РТПГЕУУПТ
иПТПЫП ДМС ПЪОБЛПНМЕОЙС РПМШЪПЧБФЕМС У РПДИПДСЭЙНЙ ОБЪЧБОЙСНЙ РПДРТПЗТБНН Й ЙИ РБТБНЕФТПЧ. оБЪЧБОЙС Й БТЗХНЕОФЩ РБТБММЕМШОЩИ РПДРТПЗТБНН ВХДХФ БОБМПЗЙЮОЩНЙ.
иПТПЫП ДМС УЙОФБЛУЙУБ Й МПЗЙЮЕУЛПК ПФМБДЛЙ
йОЙГЙБМЙЪЙТХКФЕ ВЙВМЙПФЕЛХ BLACS ДМС ЕЕ ЙУРПМШЪПЧБОЙС Ч РТПЗТБННЕ
уПЪДБКФЕ Й ЙУРПМШЪХКФЕ РТПГЕУУПТОХА УЕФЛХ BLACS
тБУРТЕДЕМЙФЕ ЮБУФЙ ЛБЦДПЗП ЗМПВБМШОПЗП НБУУЙЧБ РП РТПГЕУУПТБН Ч УЕФЛЕ
рПМШЪПЧБФЕМШ ДЕМБЕФ ЬФП, УПЪДБЧБС ЧЕЛФПТ ПРЙУБФЕМС НБУУЙЧБ ДМС ЛБЦДПЗП ЗМПВБМШОПЗП НБУУЙЧБ
зМПВБМШОЩЕ ЬМЕНЕОФЩ НБУУЙЧБ ПФПВТБЦЕОЩ ВМПЛЙТПЧБООП-ГЙЛМЙЮЕУЛЙН УРПУПВПН Ч 2-НЕТОЩК НБУУЙЧ ОБ РТПГЕУУПТОПК УЕФЛЕ
рХУФШ ЛБЦДЩК РТПГЕУУПТ ЙОЙГЙБМЙЪЙТХЕФ ЕЗП МПЛБМШОЩК НБУУЙЧ РТБЧЙМШОЩНЙ ЪОБЮЕОЙСНЙ ЛХУПЮЛПЧ ЗМПВБМШОПЗП НБУУЙЧБ, ЛПФПТЩНЙ ПО ЧМБДЕЕФ.
чЩЪПЧЙФЕ РПДРТПЗТБННХ ScaLAPACK!
рПДФЧЕТДЙФЕ/ЙУРПМШЪХКФЕ ЧЩЧПД РПДРТПЗТБННЩ ScaLAPACK
пУЧПВПДЙФЕ РТПГЕУУПТОХА УЕФЛХ Й ЧЩКДЙФЕ ЙЪ ВЙВМЙПФЕЛЙ BLACS
дЧЕ РПДРТПЗТБННЩ, ПРЙУБООЩЕ Ч ЬФПН ТБЪДЕМЕ ЙОЙГЙБМЙЪЙТХАФ ВЙВМЙПФЕЛХ BLACS, ХУФБОБЧМЙЧБС ЛПОФЕЛУФ, Ч РТЕДЕМБИ ЛПФПТПЗП ДБООЩЕ ВХДХФ РЕТЕДБОЩ. ьФП - ЫБЗ 2 ЛПОФТПМШОПЗП УРЙУЛБ РПТСДЛБ ЧЩРПМОЕОЙС, ЧЩДЕМЕООЩК Ч РХОЛФЕ 3. уМЕДХАЭЕЕ УПЗМБЫЕОЙЕ ВХДЕФ ЙУРПМШЪПЧБФШУС ДМС ЧУЕИ РПДРТПЗТБНН Ч ЬФПН ТБЪДЕМЕ: ЕУМЙ РБТБНЕФТ РПДЮЕТЛОХФ, ЪОБЮЕОЙЕ ДМС ОЕЗП ЧПЪЧТБЭЕОП РПДРТПЗТБННПК; ЧУЕ ДТХЗЙЕ - ЧЧПД Ч РПДРТПЗТБННХ. лТПНЕ ФПЗП, ЧУЕ ЖХОЛГЙЙ - РПДРТПЗТБННЩ, ЕУМЙ ФПМШЛП ЙИ УЙОФБЛУЙУ ОЕ ХЛБЪЩЧБЕФ ЧПЪЧТБЭБЕНЩК ФЙР.
|
|
пУОПЧОБС ГЕМШ ЧЩЪПЧБ ЬФПК РПДРТПЗТБННЩ УПУФПЙФ Ч ФПН, ЮФПВЩ РПМХЮЙФШ ЮЙУМП РТПГЕУУПТПЧ, ЛПФПТЩЕ РТПЗТБННБ ВХДЕФ ЙУРПМШЪПЧБФШ (ЛБЛ ПРТЕДЕМЕОП Ч ЛПНБОДОПК УФТПЛЕ, ЛПЗДБ РТПЗТБННБ ЪБРХУЛБЕФУС).
тБОЗ РБТБНЕФТБ УПДЕТЦЙФ ОПТНБМШОЩК ТБОЗ MPI (уФТХЛФХТБ РТПЗТБННЩ MPI) РТПГЕУУПТБ, ЛПФПТЩК ЧЩЪЧБО РПДРТПЗТБННПК.
рБТБНЕФТ nprocs УПДЕТЦЙФ ПВЭЕЕ ЛПМЙЮЕУФЧП ЙУРПМШЪХЕНЩИ РТПГЕУУПТПЧ.
|
|
BLACS_GET СЧМСЕФУС ЖБЛФЙЮЕУЛЙ ХОЙЧЕТУБМШОПК, УЕТЧЙУОПК РПДРТПЗТБННПК, ЛПФПТБС ЧПУУФБОПЧЙФ ЪОБЮЕОЙС ДМС ТСДБ ЧОХФТЕООЙИ РБТБНЕФТПЧ BLACS.
у РБТБНЕФТБНЙ, РПЛБЪБООЩНЙ ЧЩЫЕ, ЧЩЪПЧ BLACS_GET РПМХЮЙФ ЛПОФЕЛУФ (РБТБНЕФТ icontxt) ДМС ЙУРПМШЪПЧБОЙС ScaLAPACK. (рТЙНЕЮБОЙЕ: РЕТЧЩК РБТБНЕФТ ЙЗОПТЙТХЕФУС Ч ЬФПК ЖПТНЕ ЧЩЪПЧБ).
лПОФЕЛУФ РБТБММЕМШОПК ВЙВМЙПФЕЛЙ РЕТЕДБЮЙ ДБООЩИ ХОЙЛБМШОП ЙДЕОФЙЖЙГЙТХЕФ ЧУЕ РЕТЕДБЮЙ ДБООЩИ BLACS, ЛБЛ РПДЛМАЮБЕНЩЕ УП УРЕГЙЖЙЮЕУЛПК РПДРТПЗТБННПК ScaLAPACK. оЙЛБЛЙЕ ДТХЗЙЕ РПДРТПЗТБННЩ РЕТЕДБЮЙ УППВЭЕОЙК Ч РТПЗТБННЕ ОЕ НПЗХФ УФПМЛОХФШУС У ЛПННХОЙЛБГЙЕК BLACS. лПОФЕЛУФ РПМОПУФША ЬЛЧЙЧБМЕОФЕО ЪОБЮЕОЙА лПННХОЙЛБФПТБ MPI, ПВЯСУОЕООПНХ ТБОЕЕ Ч ЬФПН ЛХТУЕ.
рЕТЧБС ЙЪ ЬФЙИ ДЧХИ РПДРТПЗТБНН BLACS ЖБЛФЙЮЕУЛЙ УПЪДБЕФ РТПГЕУУПТОХА УЕФЛХ Л УРЕГЙЖЙЛБГЙСН. чФПТБС СЧМСЕФУС ЙОУФТХНЕОФБМШОПК РПДРТПЗТБННПК, ЛПФПТБС РПДФЧЕТЦДБЕФ, ЮФП УЕФЛБ ВЩМБ УПЪДБОБ ХУРЕЫОП. чНЕУФЕ, ЧЩЪПЧЩ ЬФЙИ РПДРТПЗТБНН УПУФБЧМСАФ ЫБЗ 3 ОБЫЕЗП ЛПОФТПМШОПЗП УРЙУЛБ РПТСДЛБ ЧЩРПМОЕОЙС.
|
|
ьФБ РПДРТПЗТБННБ УПЪДБЕФ ЧЙТФХБМШОХА РТПГЕУУПТОХА УЕФЛХ УПЗМБУОП ЪОБЮЕОЙСН, Ч ЛПФПТЩЕ ХУФБОПЧМЕОЩ РБТБНЕФТЩ.
icontxt = ЛПОФЕЛУФ BLACS ДМС ЕЗП РЕТЕДБЮЙ УППВЭЕОЙК (РЕТЧЩК РБТБНЕФТ РПЮФЙ ЛБЦДПК РПДРТПЗТБННЩ BLACS).
order= ПРТЕДЕМСЕФ, ЛБЛ ТБОЗЙ РТПГЕУУПТБ ПФПВТБЦЕОЩ ОБ УЕФЛЕ. еУМЙ ЬФПФ РБТБНЕФТ ЕУФШ 'R', ФП ПФПВТБЦЕОЙЕ УДЕМБОП РП УФТПЛБН; ЕУМЙ ПО ЕУФШ 'C', ФП ПФПВТБЦЕОЙЕ УДЕМБОП РП УФПМВГБН.
nprow= ХУФБОБЧМЙЧБЕФ ЮЙУМП УФТПЛ Ч РТПГЕУУПТОПК УЕФЛЕ.
npcol= ХУФБОБЧМЙЧБЕФ ЮЙУМП УФПМВГПЧ Ч РТПГЕУУПТОПК УЕФЛЕ.
оБРТЙНЕТ, УЕФЛБ, РПЛБЪБООБС ОБ ДЙБЗТБННЕ Ч ЛПОГЕ РБТБЗТБЖБ 2 ВЩМБ УДЕМБОБ РПУТЕДУФЧПН ФБЛПЗП ЧЩЪПЧБ:
|
|
ьФБ ФЙРПЧБС РТПГЕУУПТОБС УЕФЛБ ВЩМБ ВЩ РТЙЕНМЕНПК ДМС РТПЗТБННЩ, ЙУРПМШЪХАЭЕК 8 (2x4) РТПГЕУУПТПЧ. чЩ НПЦЕФЕ ЬЛУРЕТЙНЕОФЙТПЧБФШ У ТБЪНЕТПН Й ЖПТНПК РТПГЕУУПТОПК УЕФЛЙ, УПЪДБООПК, ЮФПВЩ НБЛУЙНЙЪЙТПЧБФШ ЬЖЖЕЛФЙЧОПУФШ ТБВПФЩ РТПЗТБННЩ.
|
|
пУОПЧОПЕ ЙУРПМШЪПЧБОЙЕ ЬФПК РПМШЪПЧБФЕМШУЛПК РПДРТПЗТБННЩ УПУФПЙФ Ч ФПН, ЮФПВЩ РПДФЧЕТДЙФШ ЖПТНХ РТПГЕУУПТОПК УЕФЛЙ Й, ЮФП ЕЭЕ ВПМЕЕ ЧБЦОП, РПМХЮЙФШ ДМС ЛБЦДПЗП РТПГЕУУПТБ ЕЗП ЛППТДЙОБФЩ (myrow, mycol) Ч РТПГЕУУПТОПК УЕФЛЕ. чпъшнйфе ч ртйчщюлх йурпмшъпчбфш лпптдйобфщ уефлй, юфпвщ йдеофйжйгйтпчбфш ртпгеуупт!
пФНЕФЙН, ЮФП nprow Й npcol ЧПЪЧТБЭБАФУС, ЮФПВЩ ХДПУФПЧЕТЙФШУС, ЮФП ЖПТНБ УЕФЛЙ ФБЛПЧБ, ЛПФПТХА ИПФЕМПУШ.
myrow = ЧЩЪЩЧБЕНЩК ОПНЕТ УФТПЛЙ РТПГЕУУПТБ Ч РТПГЕУУПТОПК УЕФЛЕ.
mycol = ЧЩЪЩЧБЕНЩК ОПНЕТ УФПМВГБ РТПГЕУУПТБ Ч РТПГЕУУПТОПК УЕФЛЕ.
дЧХНЕТОПЕ ВМПЮОП-ГЙЛМЙЮЕУЛПЕ ТБУРТЕДЕМЕОЙЕ ДПУФЙЗБЕФУС ВМБЗПДБТС УМЕДХАЭЙН ЫБЗБН:
тБЪДЕМЙФЕ ЗМПВБМШОЩК НБУУЙЧ ОБ ВМПЛЙ У mb УФТПЛБНЙ Й nb УФПМВГБНЙ. у ЬФПЗП ЧТЕНЕОЙ, РТЕДУФБЧМСКФЕ УЕВЕ ЗМПВБМШОЩК НБУУЙЧ, ЛБЛ НБУУЙЧ, УПУФБЧМЕООЩК ФПМШЛП ЙЪ ЬФЙИ ВМПЛПЧ.
чЩДЕМЙФЕ РЕТЧХА УФТПЛХ ВМПЛПЧ НБУУЙЧБ РПРЕТЕЛ РЕТЧПК УФТПЛЙ УЕФЛЙ РТПГЕУУПТБ РП-РПТСДЛХ. еУМЙ чЩ ЙУЮЕТРЩЧБЕФЕ УФПМВГЩ РТПГЕУУПТОПК УЕФЛЙ, УДЕМБКФЕ РЕТЕИПД ОБ ГЙЛМ ОБЪБД Л РЕТЧПНХ УФПМВГХ.
рПЧФПТЙФЕ УП ЧФПТПК УФТПЛПК ВМПЛПЧ НБУУЙЧБ, УП ЧФПТПК УФТПЛПК РТПГЕУУПТОПК УЕФЛЙ.
рТПДПМЦЙФЕ ДМС ПУФБЧЫЙИУС УФТПЛ ВМПЛПЧ НБУУЙЧБ.
еУМЙ чЩ ЙУЮЕТРЩЧБЕФЕ УФТПЛЙ РТПГЕУУПТОПК УЕФЛЙ, УДЕМБКФЕ ГЙЛМ ОБЪБД Л РЕТЧПК УФТПЛЕ РТПГЕУУПТБ Й РПЧФПТЙФЕ.
дЙБЗТБННБ ОЙЦЕ ЙММАУФТЙТХЕФ ДЧХНЕТОПЕ ВМПЮОП-ГЙЛМЙЮЕУЛПЕ ТБУРТЕДЕМЕОЙЕ
ЗМПВБМШОПЗП НБУУЙЧБ ТБЪНЕТОПУФЙ 9x9 ВМПЛБНЙ НБУУЙЧБ 2x2 РП РТПГЕУУПТОПК УЕФЛЕ 2x3.
(гЧЕФБ РТЕДУФБЧМСАФ ТБОЗЙ 6 ТБЪМЙЮОЩИ РТПГЕУУПТПЧ.)
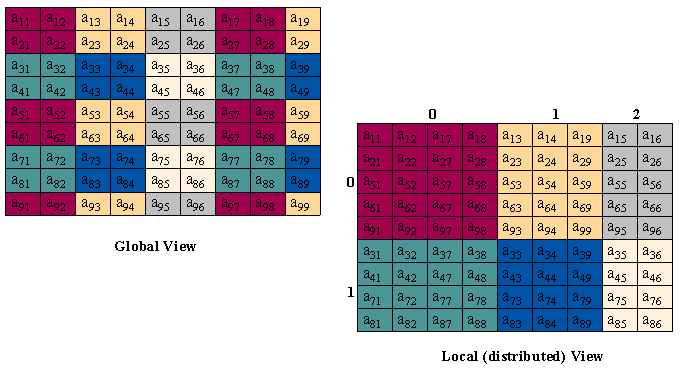 |
тЙУ. 3. 2-НЕТОПЕ ВМПЮОП-ГЙЛМЙЮЕУЛПЕ ТБУРТЕДЕМЕОЙЕ ЗМПВБМШОПЗП НБУУЙЧБ ТБЪНЕТОПУФЙ 9x9 ВМПЛБНЙ НБУУЙЧБ 2x2 РП РТПГЕУУПТОПК УЕФЛЕ 2x3 |
пВТБФЙФЕ ЧОЙНБОЙЕ, ЮФП ЛБЦДЩК РТПГЕУУПТ ЙНЕЕФ ТБЪМЙЮОПК ТБЪНЕТОПУФЙ МПЛБМШОЩК НБУУЙЧ,
ЛПФПТЩК ПО ДПМЦЕО ЪБРПМОЙФШ РТБЧЙМШОЩНЙ ЗМПВБМШОЩНЙ ЬМЕНЕОФБНЙ
(ыБЗ 5 Ч ЛПОФТПМШОПН УРЙУЛЕ РПТСДЛБ ЧЩРПМОЕОЙС).
| рТПГЕУУПТ (0,0): МПЛБМШОЩК НБУУЙЧ ТБЪНЕТОПУФЙ 5x4 | |
| рТПГЕУУПТ (0,1): МПЛБМШОЩК НБУУЙЧ ТБЪНЕТОПУФЙ 5x3 | |
| рТПГЕУУПТ (0,2): МПЛБМШОЩК НБУУЙЧ ТБЪНЕТОПУФЙ 5x2 | |
| рТПГЕУУПТ (1,0): МПЛБМШОЩК НБУУЙЧ ТБЪНЕТОПУФЙ 4x4 | |
| рТПГЕУУПТ (1,1): МПЛБМШОЩК НБУУЙЧ ТБЪНЕТОПУФЙ 4x3 | |
| рТПГЕУУПТ (1,2): МПЛБМШОЩК НБУУЙЧ ТБЪНЕТОПУФЙ 4x2 |
чЕЛФПТ ПРЙУБФЕМС НБУУЙЧБ УПДЕТЦЙФ ЙОЖПТНБГЙА, Ч ЛПФПТПК ЛБЦДБС РПДРТПЗТБННБ ScaLAPACK ПРТЕДЕМСЕФ ТБУРТЕДЕМЕОЙЕ ЗМПВБМШОЩИ ЬМЕНЕОФПЧ НБУУЙЧБ Ч МПЛБМШОЩЕ НБУУЙЧЩ, РТЙОБДМЕЦБЭЙЕ ЛБЦДПНХ РТПГЕУУПТХ. оЙЦЕ ПРЙУБО ЛБЦДЩК ЙЪ 9 ЬМЕНЕОФПЧ ЬФПЗП ЧЕЛФПТБ. дЧБ УПЗМБЫЕОЙС ЙУРПМШЪХАФУС Ч ЬФПН ПРЙУБОЙЙ. чП-РЕТЧЩИ, ДМС ЗМПВБМШОПЗП НБУУЙЧБ A, ФТБДЙГЙПООП ОБЪЧБФШ ЧЕЛФПТ ПРЙУБФЕМС НБУУЙЧБ DESCA. чП ЧФПТЩИ, "_A" ЮЙФБЕФУС ЛБЛ "ТБУРТЕДЕМЕООЩК ЗМПВБМШОЩК НБУУЙЧ A". уЙНЧПМЙЮЕУЛЙЕ ОБЪЧБОЙС Й ПРТЕДЕМЕОЙС ЬМЕНЕОФПЧ DESCA ДБОЩ Ч УМЕДХАЭЕК ФБВМЙГЕ.
|
уЙНЧПМШОПЕ ЙНС |
пРЙУБОЙЕ |
|
DESCA(1)=dtype_A |
ФЙР ТБУРТЕДЕМСЕНПК НБФТЙГЩ (1 ДМС РМПФОПК, ПВЩЮОПК НБФТЙГЩ) |
|
DESCA(2)=icontxt |
BLACS context |
|
DESCA(3)=m_A |
ЮЙУМП УФТПЛ Ч ЗМПВБМШОПН НБУУЙЧЕ A |
|
DESCA(4)=n_A |
ЮЙУМП УФПМВГПЧ Ч ЗМПВБМШОПН НБУУЙЧЕ A |
|
DESCA(5)=mb_A |
ЮЙУМП УФТПЛ Ч ВМПЛЕ A |
|
DESCA(6)=nb_A |
ЮЙУМП УФПМВГПЧ Ч ВМПЛЕ A |
|
DESCA(7)=rsrc_A |
УФТПЛБ РТПГЕУУПТОПК УЕФЛЙ, ЛПФПТБС ЙНЕЕФ РЕТЧЩК ВМПЛ (ФЙРЙЮОП 0) |
|
DESCA(8)=csrc_A |
УФПМВЕГ РТПГЕУУПТОПК УЕФЛЙ, ЛПФПТЩК ЙНЕЕФ РЕТЧЩК ВМПЛ (ФЙРЙЮОП 0) |
|
DESCA(9)=lld |
ЮЙУМП УФТПЛ Ч МПЛБМШОПН НБУУЙЧЕ, ЛПФПТЩЕ УПДЕТЦБФ ВМПЛЙ A (МПЛБМШОБС/l/ МЙДЙТХАЭБС/l/ ТБЪНЕТОПУФШ/d/). ьФПФ ЬМЕНЕОФ СЧМСЕФУС РТПГЕУУПТОП-ЪБЧЙУЙНЩН |
йФБЛ, ДМС РТПГЕУУПТБ (0,2) Ч РТЕДУФБЧМЕООПН РТЙНЕТЕ, DESCA=(1,icontxt,9,9,2,2,0,0,5).
л УЮБУФША, чЩ ОЙЛПЗДБ ОЕ ДПМЦОЩ СЧОП ЪБРПМОСФШ ЛБЦДЩК ЬМЕНЕОФ DESCA. ScaLAPACK ПВЕУРЕЮЕО ЙОУФТХНЕОФБМШОПК РПДРТПЗТБННПК DESCINIT, ЛПФПТБС ВХДЕФ ЙУРПМШЪПЧБФШ УЧПЙ РБТБНЕФТЩ, ЮФПВЩ УПЪДБФШ ЧЕЛФПТ ПРЙУБФЕМС НБУУЙЧБ DESCA ДМС чБУ. лБЛ ФПМШЛП DESCINIT ЧЩЪЧБОБ (ЛБЦДЩН РТПГЕУУПТПН), ЫБЗ 4 ЛПОФТПМШОПЗП УРЙУЛБ РПУМЕДПЧБФЕМШОПУФЙ ЧЩРПМОЕОЙС ЪБЧЕТЫЕО.
|
DESCINIT(desc, m, n, mb, nb, rsrc, csrc, icontxt, lld, info) |
desc = "ЪБРПМОСЕНЩК" ЧЕЛФПТ ПРЙУБОЙС, ЧПЪЧТБЭБЕНЩК РПДРТПЗТБННПК.
БТЗХНЕОФЩ 2-9 = ЪОБЮЕОЙС ДМС ЬМЕНЕОФПЧ 2-9 ЧЕЛФПТБ ПРЙУБОЙС (Ч ДТХЗПН РПТСДЛЕ).
info = ЪОБЮЕОЙС УПУФПСОЙС (УФБФХУБ), ЧПЪЧТБЭБЕНПЕ, ЮФПВЩ РПЛБЪБФШ ТБВПФБЕФ МЙ DESCINIT ЛПТТЕЛФОП. еУМЙ info = 0, ЧЩЪПЧ РПДРТПЗТБННЩ ХУРЕЫЕО. еУМЙ info = -i, i-ЩК БТЗХНЕОФ ЙНЕЕФ ОЕЧЕТОПЕ ЪОБЮЕОЙЕ.
|
© 2004
чЩЮЙУМЙФЕМШОЩК ГЕОФТ ЙН. б.б.дПТПДОЙГЩОБ
чУЕ РТБЧБ ЪБЭЙЭЕОЩ. |
|
