нЕТБ ВМЙЪПУФЙ ДМС ЧТЕНЕООЩИ ТСДПЧ ОБ ПУОПЧЕ ЧЕКЧМЕФ ЛПЬЖЖЙГЙЕОФПЧ
е.ч. вХТОБЕЧ, о.о. пМЕОЕЧ
нПУЛПЧУЛЙК ЖЙЪЙЛП-ФЕИОЙЮЕУЛЙК ЙОУФЙФХФ (ЗПУХДБТУФЧЕООЩК ХОЙЧЕТУЙФЕФ)
чЧЕДЕОЙЕ. нЕТБ ВМЙЪПУФЙ НЕЦДХ ДБООЩНЙ СЧМСЕФУС ГЕОФТБМШОЩН РПОСФЙЕН ВПМШЫЙОУФЧБ data mining БМЗПТЙФНПЧ. дМС “УМПЦОЩИ” ДБООЩИ, ФБЛЙИ ЛБЛ ЖЙОБОУПЧЩЕ ЧТЕНЕООЩЕ ТСДЩ, ПВЩЮОБС НЕТБ ВМЙЪПУФЙ ФЙРБ ЕЧЛМЙДПЧБ ТБУУФПСОЙС, ЪБЮБУФХА ОЕ РТЙНЕОЙНБ. оБ ТЙУ.1. ЙЪПВТБЦЕОЩ ПВНЕООЩЕ ЛХТУЩ South Africa rand Й Switzerland franc РП ПФОПЫЕОЙА Л US dollar У 01.01.90 РП 29.10.93, 1000 ПФУЮёФПЧ. пЮЕЧЙДОП, ЮФП РПДУЮЙФБООПЕ ДМС ЬФЙИ ТСДПЧ ЕЧЛМЙДПЧП ТБУУФПСОЙЕ ЪОБЮЙФЕМШОП, ИПФС, ЕУМЙ ХДБМЙФШ ФТЕОД Й РТПЧЕУФЙ РПДИПДСЭЕЕ НБУЫФБВЙТПЧБОЙЕ РП ПУЙ ПТДЙОБФ, ПЛБЦЕФУС, ЮФП ЬФЙ ЧТЕНЕООЩЕ ТСДЩ ВМЙЪЛЙ.
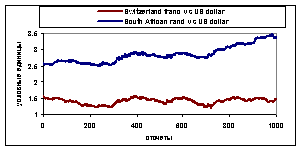
тЙУ.1. уМЕЧБ: ПВНЕООЩЕ ЛХТУЩ South Africa rand Й Switzerland franc vs US dollar У 01.01.90 РП 29.10.93, 1000 ПФУЮёФПЧ. уРТБЧБ: ФЕ ЦЕ ПВНЕООЩЕ ЛХТУЩ, ОП У ЧЩЮЕФПН ФТЕОДБ Й РПДИПДСЭЙН НБУЫФБВЙТПЧБОЙЕН РП ПУЙ ПТДЙОБФ.
йЪ ЧЩЫЕРТЙЧЕДЕООПЗП РТЙНЕТБ СУОП, ЮФП НЕТХ ВМЙЪПУФЙ ЧТЕНЕООПЗП ТСДБ УМЕДХЕФ ТБУУЮЙФЩЧБФШ ОБ ПУОПЧЕ ОЕЛПФПТЩИ ИБТБЛФЕТЙУФЙЛ ЧТЕНЕООПЗП ТСДБ, Б ОЕ ОБ ПУОПЧЕ ЪОБЮЕОЙК ТСДБ. рТЙЮЕН ЬФЙ ИБТБЛФЕТЙУФЙЛЙ ДПМЦОЩ ВЩФШ ТПВБУФОЩ РП ПФОПЫЕОЙА Л ЙЪНЕОЕОЙСН Ч ХТПЧОЕ, НБУЫФБВЕ Й ФТЕОДЕ ТСДБ. ч ТБВПФЕ РТЕДМБЗБАФУС НЕТЩ ВМЙЪПУФЙ ДМС ЧТЕНЕООЩИ ТСДПЧ ОБ ПУОПЧЕ ЧЕКЧМЕФ ЛПЬЖЖЙГЙЕОФПЧ, ТБУУЮЙФЩЧБЕНЩИ У РПНПЭША ДЙУЛТЕФОПЗП ЧЕКЧМЕФ РТЕПВТБЪПЧБОЙС Й ПВМБДБАЭЙИ ЬФЙНЙ УЧПКУФЧБНЙ.
дЙУЛТЕФОПЕ
ЧЕКЧМЕФ РТЕПВТБЪПЧБОЙЕ. рХУФШ ![]() - ЧТЕНЕООПК ТСД,
- ЧТЕНЕООПК ТСД, ![]() ДМС ОЕЛПФПТПЗП
ГЕМПЗП
ДМС ОЕЛПФПТПЗП
ГЕМПЗП ![]() Й
Й
![]() .
рХУФШ
.
рХУФШ ![]() -
НБФТЙГБ ДЙУЛТЕФОПЗП ЧЕКЧМЕФ РТЕПВТБЪПЧБОЙС ТБЪНЕТБ
-
НБФТЙГБ ДЙУЛТЕФОПЗП ЧЕКЧМЕФ РТЕПВТБЪПЧБОЙС ТБЪНЕТБ ![]() , ПРТЕДЕМЕООБС ОБ ПУОПЧЕ ЧЕКЧМЕФ
Й НБУЫФБВОПЗП ЖЙМШФТПЧ ДМЙОЩ
, ПРТЕДЕМЕООБС ОБ ПУОПЧЕ ЧЕКЧМЕФ
Й НБУЫФБВОПЗП ЖЙМШФТПЧ ДМЙОЩ ![]() [1]. чЕЛФПТ ЧЕКЧМЕФ Й НБУЫФБВОЩИ
ЛПЬЖЖЙГЙЕОФПЧ ТБЧЕО
[1]. чЕЛФПТ ЧЕКЧМЕФ Й НБУЫФБВОЩИ
ЛПЬЖЖЙГЙЕОФПЧ ТБЧЕО ![]() , ЗДЕ
, ЗДЕ ![]() Й
Й ![]() - ЧЕЛФПТБ ДМЙОЩ
- ЧЕЛФПТБ ДМЙОЩ ![]() Й
Й ![]() УППФЧЕФУФЧЕООП.
рХУФШ
УППФЧЕФУФЧЕООП.
рХУФШ ![]() ,
ФПЗДБ
,
ФПЗДБ ![]() -
РТПРПТГЙПОБМШОП УТЕДОЕНХ ТСДБ, РТЙЮЕН ЕУМЙ Ч ЧЕЛФПТЕ
-
РТПРПТГЙПОБМШОП УТЕДОЕНХ ТСДБ, РТЙЮЕН ЕУМЙ Ч ЧЕЛФПТЕ ![]() ПВОХМЙФШ
ПВОХМЙФШ ![]() , Б РПФПН
УДЕМБФШ ПВТБФОПЕ ЧЕКЧМЕФ РТЕПВТБЪПЧБОЙЕ, ФП ЬФП ТБЧОПУЙМШОП ЧЩЮЙФБОЙА УТЕДОЕЗП
ЙЪ ТСДБ
, Б РПФПН
УДЕМБФШ ПВТБФОПЕ ЧЕКЧМЕФ РТЕПВТБЪПЧБОЙЕ, ФП ЬФП ТБЧОПУЙМШОП ЧЩЮЙФБОЙА УТЕДОЕЗП
ЙЪ ТСДБ ![]() .
лПЬЖЖЙГЙЕОФ
.
лПЬЖЖЙГЙЕОФ ![]() РТПРПТГЙПОБМЕО
ТБЪОПУФЙ УНЕЦОЩИ ЧЪЧЕЫЕООЩИ УТЕДОЙИ ДМЙОЩ
РТПРПТГЙПОБМЕО
ТБЪОПУФЙ УНЕЦОЩИ ЧЪЧЕЫЕООЩИ УТЕДОЙИ ДМЙОЩ ![]() , ФП ЕУФШ ХЛБЪЩЧБЕФ ОБ ЙЪНЕОЕОЙЕ
ЪОБЮЕОЙК ТСДБ ОБ НБУЫФБВЕ
, ФП ЕУФШ ХЛБЪЩЧБЕФ ОБ ЙЪНЕОЕОЙЕ
ЪОБЮЕОЙК ТСДБ ОБ НБУЫФБВЕ ![]() . нПДХМШ
. нПДХМШ ![]() РПЛБЪЩЧБЕФ, УЛПМШЛП ЬОЕТЗЙЙ ТСДБ
РПЛБЪЩЧБЕФ, УЛПМШЛП ЬОЕТЗЙЙ ТСДБ
![]() УПДЕТЦЙФУС
Ч ПФТЕЪЛЕ ЮБУФПФ
УПДЕТЦЙФУС
Ч ПФТЕЪЛЕ ЮБУФПФ ![]() Ч НПНЕОФ ЧТЕНЕОЙ
Ч НПНЕОФ ЧТЕНЕОЙ ![]() . дМС ЫЙТПЛПЗП ЛМБУУБ
УФПИБУФЙЮЕУЛЙИ РТПГЕУУПЧ
. дМС ЫЙТПЛПЗП ЛМБУУБ
УФПИБУФЙЮЕУЛЙИ РТПГЕУУПЧ ![]() ОЕЪБЧЙУЙНЩ, Й ТБУРТЕДЕМЕОЩ ЛБЛ
ОЕЪБЧЙУЙНЩ, Й ТБУРТЕДЕМЕОЩ ЛБЛ ![]() , ЗДЕ
, ЗДЕ ![]() - ОЕЛПФПТБС
ЛПОУФБОФБ [1]. лПЬЖЖЙГЙЕОФ
- ОЕЛПФПТБС
ЛПОУФБОФБ [1]. лПЬЖЖЙГЙЕОФ ![]() РТПРПТГЙПОБМЕО ЧЪЧЕЫЕООПНХ УТЕДОЕНХ ДМЙОЩ
РТПРПТГЙПОБМЕО ЧЪЧЕЫЕООПНХ УТЕДОЕНХ ДМЙОЩ ![]() , Б ЕЗП НПДХМШ
РПЛБЪЩЧБЕФ, УЛПМШЛП ЬОЕТЗЙЙ ТСДБ
, Б ЕЗП НПДХМШ
РПЛБЪЩЧБЕФ, УЛПМШЛП ЬОЕТЗЙЙ ТСДБ ![]() УПДЕТЦЙФУС Ч ПФТЕЪЛЕ ЮБУФПФ
УПДЕТЦЙФУС Ч ПФТЕЪЛЕ ЮБУФПФ ![]() Ч НПНЕОФ
ЧТЕНЕОЙ
Ч НПНЕОФ
ЧТЕНЕОЙ ![]() .
ч ТБВПФЕ ВХДХФ ЙУРПМШЪПЧБФШУС ЧЕКЧМЕФ Й НБУЫФБВОЩЕ ЖЙМШФТЩ дПВЕЫЙ 4 (
.
ч ТБВПФЕ ВХДХФ ЙУРПМШЪПЧБФШУС ЧЕКЧМЕФ Й НБУЫФБВОЩЕ ЖЙМШФТЩ дПВЕЫЙ 4 (![]() ). ч ЬФПН УМХЮБЕ
). ч ЬФПН УМХЮБЕ
![]() ОЕ
ЮХЧУФЧЙФЕМШОЩ Л МЙОЕКОПНХ ФТЕОДХ, ФП ЕУФШ ЕУМЙ ТСД
ОЕ
ЮХЧУФЧЙФЕМШОЩ Л МЙОЕКОПНХ ФТЕОДХ, ФП ЕУФШ ЕУМЙ ТСД ![]() УХФШ ЪОБЮЕОЙС ОЕЛПФПТПК МЙОЕКОПК
ЖХОЛГЙЙ, ФП
УХФШ ЪОБЮЕОЙС ОЕЛПФПТПК МЙОЕКОПК
ЖХОЛГЙЙ, ФП ![]() .
рТЙ РПДУЮЕФЕ ЧЕЛФПТБ ЛПЬЖЖЙГЙЕОФПЧ
.
рТЙ РПДУЮЕФЕ ЧЕЛФПТБ ЛПЬЖЖЙГЙЕОФПЧ ![]() ОЕСЧОП ДЕМБЕФУС РТЕДРПМПЦЕОЙЕ П
ЧПЪНПЦОПУФЙ ГЙЛМЙЮЕУЛПЗП РТПДПМЦЕОЙС ТСДБ
ОЕСЧОП ДЕМБЕФУС РТЕДРПМПЦЕОЙЕ П
ЧПЪНПЦОПУФЙ ГЙЛМЙЮЕУЛПЗП РТПДПМЦЕОЙС ТСДБ ![]() :
:![]() . еУМЙ ЬФП ОЕ ФБЛ, ФП ЪОБЮЕОЙС “ЗТБОЙЮОЩИ”
ЧЕКЧМЕФ ЛПЬЖЖЙГЙЕОФПЧ ВХДХФ РПДУЮЙФБОЩ ОЕЧЕТОП. дМС ЖЙМШФТПЧ дПВЕЫЙ 4 ЬФП
ЛПЬЖЖЙГЙЕОФЩ
. еУМЙ ЬФП ОЕ ФБЛ, ФП ЪОБЮЕОЙС “ЗТБОЙЮОЩИ”
ЧЕКЧМЕФ ЛПЬЖЖЙГЙЕОФПЧ ВХДХФ РПДУЮЙФБОЩ ОЕЧЕТОП. дМС ЖЙМШФТПЧ дПВЕЫЙ 4 ЬФП
ЛПЬЖЖЙГЙЕОФЩ ![]() ,
,
![]() Й
Й ![]()
![]() .
.
бМЗПТЙФН РПДУЮЕФБ НЕТ ВМЙЪПУФЙ НЕЦДХ ЧТЕНЕООЩНЙ ТСДБНЙ.
- рХУФШ ТСДЩ
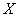 Й
Й 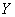 ЙНЕАФ
ПДЙОБЛПЧХА ДМЙОХ. рПДУЮЙФЩЧБЕН ЧЕКЧМЕФ ЛПЬЖЖЙГЙЕОФЩ
ЙНЕАФ
ПДЙОБЛПЧХА ДМЙОХ. рПДУЮЙФЩЧБЕН ЧЕКЧМЕФ ЛПЬЖЖЙГЙЕОФЩ 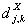 Й
Й 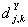 ДМС
ДМС 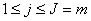 Й
ПВОХМСЕН “ЗТБОЙЮОЩЕ” ЛПЬЖЖЙГЙЕОФЩ.
Й
ПВОХМСЕН “ЗТБОЙЮОЩЕ” ЛПЬЖЖЙГЙЕОФЩ. - рПМПЦЙН
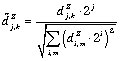 , ЗДЕ
, ЗДЕ 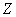 ПВПЪОБЮБЕФ
МЙВП ,
МЙВП .
чЕЛФПТБ ЛПЬЖЖЙГЙЕОФПЧ
ПВПЪОБЮБЕФ
МЙВП ,
МЙВП .
чЕЛФПТБ ЛПЬЖЖЙГЙЕОФПЧ 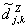 РТЕДУФБЧМСАФ ИБТБЛФЕТЙУФЙЛЙ ТСДБ,
ЛПФПТЩЕ, ЛБЛ УМЕДХЕФ ЙЪ ЧЩЫЕРТЙЧЕДЕООЩИ УЧПКУФЧ ЧЕКЧМЕФ ЛПЬЖЖЙГЙЕОФПЧ, 1)
ТПВБУФОЩ РП ПФОПЫЕОЙА Л ЙЪНЕОЕОЙА УТЕДОЕЗП ТСДБ, ФТЕОДХ, НБУЫФБВЙТПЧБОЙА
2) ОЕЪБЧЙУЙНЩ Й ОПТНБМШОП ТБУРТЕДЕМЕОЩ. дМЙОБ ФБЛПЗП ЧЕЛФПТБ ИБТБЛФЕТЙУФЙЛ
ТБЧОБ
РТЕДУФБЧМСАФ ИБТБЛФЕТЙУФЙЛЙ ТСДБ,
ЛПФПТЩЕ, ЛБЛ УМЕДХЕФ ЙЪ ЧЩЫЕРТЙЧЕДЕООЩИ УЧПКУФЧ ЧЕКЧМЕФ ЛПЬЖЖЙГЙЕОФПЧ, 1)
ТПВБУФОЩ РП ПФОПЫЕОЙА Л ЙЪНЕОЕОЙА УТЕДОЕЗП ТСДБ, ФТЕОДХ, НБУЫФБВЙТПЧБОЙА
2) ОЕЪБЧЙУЙНЩ Й ОПТНБМШОП ТБУРТЕДЕМЕОЩ. дМЙОБ ФБЛПЗП ЧЕЛФПТБ ИБТБЛФЕТЙУФЙЛ
ТБЧОБ 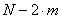 .
. - рХУФШ
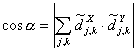 -
ЛПУЙОХУ ХЗМБ НЕЦДХ ЧЕЛФПТБНЙ ИБТБЛФЕТЙУФЙЛ. рПМПЦЙН
-
ЛПУЙОХУ ХЗМБ НЕЦДХ ЧЕЛФПТБНЙ ИБТБЛФЕТЙУФЙЛ. рПМПЦЙН 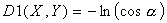 Й
Й 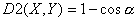 .
рПУЛПМШЛХ ЛПЬЖЖЙГЙЕОФ ИБТБЛФЕТЙЪХЕФ ЙЪНЕОЕОЙЕ Ч ЪОБЮЕОЙСИ
ТСДБ ОБ
ПРТЕДЕМЕООПН НБУЫФБВЕ Ч ПРТЕДЕМЕООЩК НПНЕОФ ЧТЕНЕОЙ, ФП ДМС ЖЙМШФТБ дПВЕЫЙ
4 ЙНЕЕФ УНЩУМ ПРТЕДЕМЙФШ НЕТЩ ВМЙЪПУФЙ ОБ ПУОПЧЕ ЪОБЮЕОЙС
.
рПУЛПМШЛХ ЛПЬЖЖЙГЙЕОФ ИБТБЛФЕТЙЪХЕФ ЙЪНЕОЕОЙЕ Ч ЪОБЮЕОЙСИ
ТСДБ ОБ
ПРТЕДЕМЕООПН НБУЫФБВЕ Ч ПРТЕДЕМЕООЩК НПНЕОФ ЧТЕНЕОЙ, ФП ДМС ЖЙМШФТБ дПВЕЫЙ
4 ЙНЕЕФ УНЩУМ ПРТЕДЕМЙФШ НЕТЩ ВМЙЪПУФЙ ОБ ПУОПЧЕ ЪОБЮЕОЙС 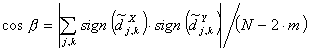 . рПМПЦЙН
. рПМПЦЙН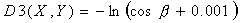 (ДПВБЧЛБ
(ДПВБЧЛБ
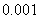 ОХЦОБ
ОБ ФПФ УМХЮБК, ЕУМЙ РЕТЧПЕ УМБЗБЕНПЕ Ч БТЗХНЕОФЕ МПЗБТЙЖНБ ТБЧОП ОХМА) Й
ОХЦОБ
ОБ ФПФ УМХЮБК, ЕУМЙ РЕТЧПЕ УМБЗБЕНПЕ Ч БТЗХНЕОФЕ МПЗБТЙЖНБ ТБЧОП ОХМА) Й 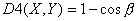 .
рТЕЙНХЭЕУФЧП
.
рТЕЙНХЭЕУФЧП 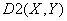 Й
Й 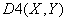 Ч ФПН, ЮФП ЬФЙ НЕТЩ
ВМЙЪПУФЙ ПЗТБОЙЮЕОЩ. лБЮЕУФЧЕООПК ТБЪОЙГЩ НЕЦДХ , Й
Ч ФПН, ЮФП ЬФЙ НЕТЩ
ВМЙЪПУФЙ ПЗТБОЙЮЕОЩ. лБЮЕУФЧЕООПК ТБЪОЙГЩ НЕЦДХ , Й 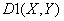 ,
, 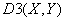 ОЕФ.
ОЕФ.
фЕУФЙТПЧБОЙЕ
НЕТ ВМЙЪПУФЙ. дМС ФЕУФЙТПЧБОЙС ЧЧЕДЕООЩИ НЕТ
ВМЙЪПУФЙ ЙУРПМШЪПЧБМЙУШ ТСДЩ ПВНЕООЩИ ЛХТУПЧ 30 ЧБМАФ РП ПФОПЫЕОЙА Л US dollar, ЧЪСФЩЕ У УБКФБ Federal Reserve Statistical Release, USA c 26.02.91 РП 31.12.98, 2048 ПФУЮЕФПЧ (www.federalreserve.gov/releases/h10/hist/default1999.htm). ч ФБВМ.1. РТЙЧЕДЕОЩ
ЪОБЮЕОЙС НЕТ ВМЙЪПУФЙ ![]() Й
Й ![]() НЕЦДХ ЛХТУПН Switzerland franc Й ПУФБМШОЩНЙ ПВНЕООЩНЙ ЛХТУБНЙ. фБЛЦЕ Ч ФБВМЙГЕ РТЙЧЕДЕОЩ ТЕЪХМШФБФЩ
ТБЪВЙЕОЙС ТСДПЧ ОБ 10 ЛМБУФЕТПЧ У РПНПЭША БМЗПТЙФНБ k-Means [2] (Ч УФПМВГБИ ХЛБЪБОЩ ОПНЕТБ ЛМБУФЕТПЧ, Л ЛПФПТЩН РТЙОБДМЕЦБФ ТСДЩ).
рТЙ ТБЪВЙЕОЙЙ ОБ ЛМБУФЕТЩ ЙУРПМШЪПЧБМЙУШ ДЧБ ФЙРБ ТБУУФПСОЙС НЕЦДХ ТСДБНЙ: cs
– ОБ ПУОПЧЕ ЛПУЙОХУБ ХЗМБ Й cr – ОБ ПУОПЧЕ
ЛПЬЖЖЙГЙЕОФБ ЛПТТЕМСГЙЙ НЕЦДХ ТСДБНЙ. йЪ ФБВМ.1 ЧЙДОП, ЮФП НЕЦДХ ЧЧЕДЕООЩНЙ
НЕТБНЙ ВМЙЪПУФЙ Й ТБЪВЙЕОЙЕН ОБ ЛМБУФЕТЩ, РП ЛТБКОЕК НЕТЕ ДМС РЕТЧЩИ 10 ЧБМАФ,
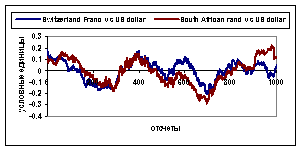
УХЭЕУФЧХЕФ ТБЪХНОПЕ УППФЧЕФУФЧЙЕ. оБ ТЙУ.2. ЙЪПВТБЦЕОБ ЪБЧЙУЙНПУФШ НЕТ ВМЙЪПУФЙ
НЕЦДХ ЛХТУПН Switzerland franc Й ПУФБМШОЩНЙ ПВНЕООЩНЙ ЛХТУБНЙ. фБЛЦЕ Ч ФБВМЙГЕ РТЙЧЕДЕОЩ ТЕЪХМШФБФЩ
ТБЪВЙЕОЙС ТСДПЧ ОБ 10 ЛМБУФЕТПЧ У РПНПЭША БМЗПТЙФНБ k-Means [2] (Ч УФПМВГБИ ХЛБЪБОЩ ОПНЕТБ ЛМБУФЕТПЧ, Л ЛПФПТЩН РТЙОБДМЕЦБФ ТСДЩ).
рТЙ ТБЪВЙЕОЙЙ ОБ ЛМБУФЕТЩ ЙУРПМШЪПЧБМЙУШ ДЧБ ФЙРБ ТБУУФПСОЙС НЕЦДХ ТСДБНЙ: cs
– ОБ ПУОПЧЕ ЛПУЙОХУБ ХЗМБ Й cr – ОБ ПУОПЧЕ
ЛПЬЖЖЙГЙЕОФБ ЛПТТЕМСГЙЙ НЕЦДХ ТСДБНЙ. йЪ ФБВМ.1 ЧЙДОП, ЮФП НЕЦДХ ЧЧЕДЕООЩНЙ
НЕТБНЙ ВМЙЪПУФЙ Й ТБЪВЙЕОЙЕН ОБ ЛМБУФЕТЩ, РП ЛТБКОЕК НЕТЕ ДМС РЕТЧЩИ 10 ЧБМАФ,
УХЭЕУФЧХЕФ ТБЪХНОПЕ УППФЧЕФУФЧЙЕ. оБ ТЙУ.2. ЙЪПВТБЦЕОБ ЪБЧЙУЙНПУФШ НЕТ ВМЙЪПУФЙ
![]() Й
Й ![]() НЕЦДХ Switzerland
franc Й Australia dollar, Austria schilling, China yuan, Finland markka,
France franc, Hong-Kong dollar
ПФ ЧТЕНЕОЙ. ъОБЮЕОЙС
НЕЦДХ Switzerland
franc Й Australia dollar, Austria schilling, China yuan, Finland markka,
France franc, Hong-Kong dollar
ПФ ЧТЕНЕОЙ. ъОБЮЕОЙС ![]() Й
Й ![]() ПГЕОЙЧБМЙУШ Ч УЛПМШЪСЭЕН ПЛОЕ ДМЙОПК 256
ПФУЮЕФПЧ, ДМС РПДУЮЕФБ ЙУРПМШЪПЧБМЙУШ 401 ПФУЮЕФ У 01.01.90 РП 15.07.91. йЪ
ТЙУ.2. ЧЙДОП, ЮФП ЛХТУЩ ЧБМАФ ПВТБЪХАФ ЛМБУФЕТЩ, ЛПФПТЩЕ ЪБЧЙУСФ ПФ ЧТЕНЕОЙ. рП
ЧУЕК ЧЙДЙНПУФЙ, ЬФП ПУОПЧОБС РТЙЮЙОБ, ЙЪ-ЪБ ЛПФПТПК Ч ФБВМ.1. ДМС РПУМЕДОЙИ
15-20 ЧБМАФ УППФЧЕФУФЧЙЕ НЕЦДХ ЪОБЮЕОЙСНЙ НЕТ ВМЙЪПУФЙ
ПГЕОЙЧБМЙУШ Ч УЛПМШЪСЭЕН ПЛОЕ ДМЙОПК 256
ПФУЮЕФПЧ, ДМС РПДУЮЕФБ ЙУРПМШЪПЧБМЙУШ 401 ПФУЮЕФ У 01.01.90 РП 15.07.91. йЪ
ТЙУ.2. ЧЙДОП, ЮФП ЛХТУЩ ЧБМАФ ПВТБЪХАФ ЛМБУФЕТЩ, ЛПФПТЩЕ ЪБЧЙУСФ ПФ ЧТЕНЕОЙ. рП
ЧУЕК ЧЙДЙНПУФЙ, ЬФП ПУОПЧОБС РТЙЮЙОБ, ЙЪ-ЪБ ЛПФПТПК Ч ФБВМ.1. ДМС РПУМЕДОЙИ
15-20 ЧБМАФ УППФЧЕФУФЧЙЕ НЕЦДХ ЪОБЮЕОЙСНЙ НЕТ ВМЙЪПУФЙ ![]() ,
, ![]() Й ОПНЕТБНЙ ЛМБУФЕТПЧ,
РПМХЮЕООЩИ У РПНПЭША БМЗПТЙФНБ K-means, ОЕ ПЮЕОШ ИПТПЫЕЕ.
Й ОПНЕТБНЙ ЛМБУФЕТПЧ,
РПМХЮЕООЩИ У РПНПЭША БМЗПТЙФНБ K-means, ОЕ ПЮЕОШ ИПТПЫЕЕ.
тБВПФБ РПДДЕТЦБОБ ЗТБОФПН тжжй № 04-07-90346, РТПЗТБННПК оы-1843.2003.01, ГЕМЕЧПК РТПЗТБННПК рТЕЪЙДЙХНБ тбо «йОЖПТНБФЙЪБГЙС».
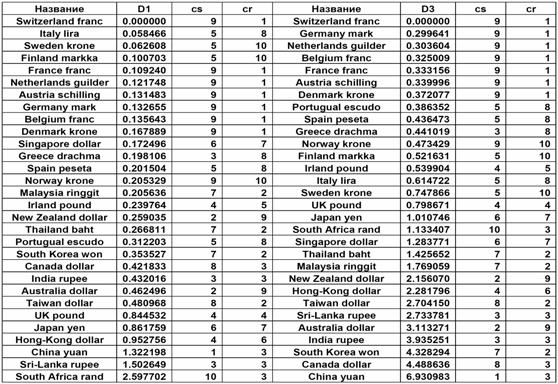
фБВМ.1.
ъОБЮЕОЙС НЕТ ВМЙЪПУФЙ ![]() Й
Й ![]() Й ТЕЪХМШФБФЩ ЛМБУФЕТОПЗП БОБМЙЪБ.
Й ТЕЪХМШФБФЩ ЛМБУФЕТОПЗП БОБМЙЪБ.
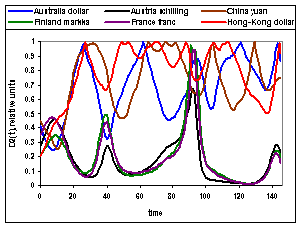
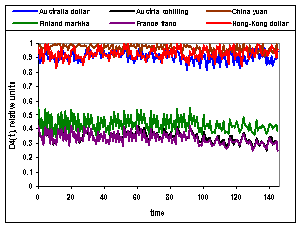
тЙУ.2.
ъБЧЙУЙНПУФШ НЕТ ВМЙЪПУФЙ ![]() Й
Й ![]() ПФ ЧТЕНЕОЙ.
ПФ ЧТЕНЕОЙ.
мЙФЕТБФХТБ.
1. Vidakovic B. Statistical modeling by wavelets, Wiley, 1999.
2. Kaufman L., Rousseeuw P.J., Finding Groups in Data: An Introduction to Cluster Analysis, Wiley, 1990.