Вычислительный центр им. А.А. Дородницына РАНРаздел виртуального курса
|
|

MPI коллективный обмен сообщениями I
Содержание
1. Введение
2. Функции MPI по коллективной коммуникации
2.1 Характеристики
2.2 Функция барьерной синхронизации
2.3 Функции перемещения данных
2.3.1 Broadcast (пересылка сообщений "один-всем")
2.3.2 Gather (сборка "каждый-одному") и Scatter (размещение "один-каждому")
2.3.3 Gatherv (гибкая сборка "переменный
каждый-одному") и
Scatterv (гибкое размещение "переменный один-каждому")
2.3.4 Allgather (всеобщая сборка "все-каждому")
2.3.5 Alltoall (всеобщий обмен "каждый-каждому")
2.4 Функции глобальных вычислений
3. Проблемы эффективности работы
3.1 Пример: Широкое распространение по 8 процессам
3.2 Пример: Размещение по 8 процессам
1. Введение
Коллективная коммуникация включают все процессы в коммуникаторе. (Коммуникаторы были введены в модуле по основам MPI программирования .) Цель коллективной коммуникации состоит в том, чтобы управлять "общим" куском или набором информации. Функции коллективной коммуникации были построены при использовании функций попарной коммуникации. Функции коллективной коммуникации могут быть построены и вручную, но это довольно утомительно и не столь эффективно.
Хотя другие библиотеки передачи сообщений обеспечивают определенные вызовы коллективных коммуникаций, ни одна из них не обеспечивает набор функций коллективной коммуникации столь же полный и над╦жный в эксплуатации, как предоставленные библиотекой MPI. В этой лекции мы вводим эти функции в трех категориях: синхронизация, перемещение данных и глобальные вычисления.
2. Функции MPI по коллективной коммуникации
- Барьерная синхронизация
- Пересылка ссобщений от одного участника всем другим участникам (Broadcast)
- Сборка данных из массива, распределенного по процессам, в один массив (Gather)
- Распределение данных от одного участника всем остальным участникам (Scatter)
- Обмен данных "каждый-каждому" (all-to-all)
- Глобальное преобразование (reduction) (например, нахождение суммы, минимума "общих" элементов данных)
- Поиск (scan) по всем участникам коммуникатора
2.1 Характеристики
Функции MPI для коллективной коммуникации отличаются по разным признакам от функций MPI для попарной коммуникации, которые были введены в модуле MPI попарный обмен сообщениями I. Ниже перечислены особенности функций коллективной коммуникации MPI:
- Включают скоординированную коммуникацию в пределах группы процессов, идентифицированных коммуникатором MPI
- Заменяют более сложную последовательность запросов попарных вызовов
- Все функции будут блокированы до тех пор, пока они локально не завершатся
- Коммуникации могут или могут не быть синхронизированы (в зависимости от реализации)
- В некоторых случаях корневой процесс порождает или получает все данные
- Количество отправленных данных должно точно соответствовать количеству данных, указанных получателем
- Функции имеют много модификаций по отношению к основному виду
- Нет нужды в тегах сообщений
Коллективные коммуникации MPI можно разбить на три подмножества: синхронизация, перемещение данных и глобальные вычисления, которые охвачены в следующих трех разделах.
2.2 Функция барьерной синхронизации
В параллельных приложениях в среде с распределенной памятью, иногда требуется явная или неявная синхронизация. Подобно другим библиотекам передачи сообщений, MPI обеспечивает функциональный запрос MPI_Barrier, чтобы синхронизировать все процессы в пределах коммуникатора. Барьер является элементарной синхронизацией. Узел, вызывающий его, будет блокирован, пока все узлы в пределах группы не вызвали MPI_Barrier. Синтаксис MPI_Barrier для C приведен ниже:
C
|
|
|
где:
|
|
является предопределенной структурой MPI для коммуникаторов, а |
|
comm |
- некий коммуникатор. |
2.3 Функции перемещения данных
MPI обеспечивает три типа коллективных функций для перемещения данных. Это пересылка сообщений "один-всем" (broadcast), сборка "каждый-одному" (gather) и размещение "один-каждому" (scatter). Имеются также функции всеобщей сборки "все-каждому" (allgather) и всеобщего обмена "каждый-каждому" (alltoall). Функции сборки (gather), распределения (scatter), всеобщей сборки (allgather) и всеобщего обмена (alltoall) также имеют версии и для переменных данных. Для их этих версий каждый процесс может отправить и/или получить различное число элементов. Ниже приведен список всех функций коллективного перемещения данных MPI:
- broadcast
- gather, gatherv
- scatter, scatterv
- allgather, allgatherv
- alltoall, alltoallv
Далее будут описаны функциональные возможности и синтаксис этих функций.
2.3.1 Broadcast (распространение "один-всем")
Во многих случаях, один процесс должен отправить (broadcast) некоторые данные (скаляр или вектор) всем процессам в группе. Для выполнения этой задачи в MPI есть элементарная передача MPI_Bcast. Синтаксис MPI_Bcast задается следующим образом:
C
|
|
|
где:
|
buffer |
- стартовый адрес буфера, |
|
count |
- целое число, указывающее число элементов данных в буфере, |
|
datatype |
- определенная константа MPI, указывающая тип элементов данных в буфере, |
|
root |
является целым числом, указывающим ранг корневого процесса широкого распространения, и |
|
comm |
является коммуникаторм.. |
Функция MPI_Bcast должна быть вызвана каждым узлом в группе, определяя те же самые comm и root. Сообщение отправляется из корневого процесса ко всем процессам в группе, включая корневой процесс.
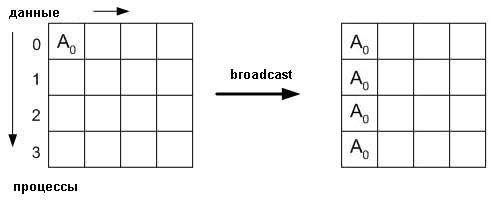
Пример:
- Пример "hello, world" использован в более ранних модулях.
- Можно применить пересылку "один-всем" (broadcast) вместо многочисленных отправок и получений.
char message[20];
int rank, root = 0;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if (rank == root) {
strcpy(message, "Hello, world!");
}
MPI_Bcast(message, 14, MPI_CHAR, root, & MPI_COMM_WORLD);
printf( "Message from process = %d : %.14s\n", rank,message);
2.3.2 Gather (сборка "каждый-одному") и Scatter (размещение "один-каждому")
Если массив распределен по всем процессам в группе, и необходимо собрать каждую часть массива в определенный массив в порядке рангов процессов, используют Gather. С другой стороны, если необходимо распределить данные на n равных долей, когда i-й сегмент отправляют i-му процессу в группе, которая имеет n процессов, используют Scatter. MPI обеспечивает два варианта операций gather/scatter: один вариант, в котором количество элементов данных собранных от узлов/отправленных к узлам может отличаться; и другой, более эффективный вариант для специального случая, когда количество элементов данных на узел одно и то же. Синтаксис этих операций приведен ниже:
C
|
|
|
|
|
|
где, для функции Gather:
|
sbuf |
- стартовый адрес буфера отправителя, |
|
scount |
- количество элементов в буфере отправки, |
|
stype |
- тип данных элементов буфера отправки, |
|
rbuf |
- стартовый адрес буфера получателя, |
|
rcount |
- количество элементов для любого однократного получения, |
|
rtype |
- тип данных элементов буфера получателя, |
|
root |
- ранг процесса получателя и |
|
comm |
- коммуникатор. |
Отметим, что rbuf, rcount, rtype имеют значение только для корневого процесса.
и для функции Scatter:
|
sbuf |
- адрес буфера отправителя, |
|
scount |
- колечество элементов, отправленных каждому процессу, |
|
stype |
- тип данных элементов буфера отправителя, |
|
rbuf |
- адрес буфера получателя, |
|
rcount |
- число элементов в буфере получателя, |
|
rtype |
- тип данных элементов буфера получателя, |
|
root |
- ранг процесса отправителя и |
|
comm |
- коммуникатор. |
Отметим, что sbuf, scount, stype имеют значение только для корневого процесса.
В операции сборки (gather), каждый процесс (включая корневой процесс) отправляет scount элементов типа stype из sbuf к корневому процессу. Корневой процесс получает сообщения и запоминает их в порядке рангов в rbuf. Для распределения (scatter) все происходит в обратном порядке. Корневой процесс отправляет буфер из N кусков данных (N = числу процессов в группе) так, чтобы процесс 1 получил первый элемент, процесс 2 получил второй элемент, и т.д.
Действие Gather и Scatter
Для иллюстрации действия функций ниже приведен рисунок:
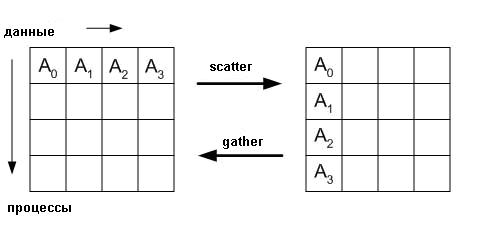
В дополнении к рисунку ниже приведен пример задачи, которая призвана проиллюстрировать действие функции gather (сборки "каждый-одному").
- Умножение матрицы на вектор для матрицы, распределенной по строкам
- Необходимо подсчитать весь выходной вектор, поскольку он нужен для одного процесса
Типовой код
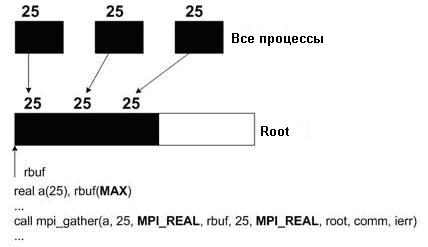
Задача, связанная с нижеприведенной программой, заключается в умножении матрицы A размера 100x100 на вектор B длины 100. Так как этот пример использует 4 процессора, каждый процессор будет обрабатывать свой собственный кусок в 25 строк матрицы A. Вектор B √ один и тот же для каждой задачи. Вектор C будет иметь 25 элементов, рассчитанных каждым процессором, и сохраненных в cpart. Функция MPI_Gather возьмет cpart от каждой задачи и сохранит результат в ctotal. Это и будет полный вектор C.
doublea[100,25],b[100],cpart[25],ctotal[100];
int root;
root=0; for(i=0;i<25;i++) { cpart[i]=0; for(k=0;k<100;k++) { cpart[i]=cpart[i]+a[k,i]*b[k]; } } MPI_Gather(cpart,25,MPI_REAL,ctotal,25,MPI_REAL,root,MPI_COMM_WORLD);
A: матрица, распределенная по строкам
b: вектор, используемый совместно всеми процессорами
c: вектор, обновляемый каждым процессором независимо от других процессоров
Ниже приведены два фрагмента программы на ФОРТРАНе, чтобы еще более полно проиллюстрировать использование MPI_Gather и MPI_Scatter.
MPI_GATHER
MPI_SCATTER
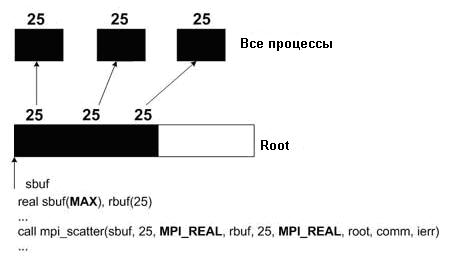
Нетрудно представить себе аналогичные фрагменты на С.
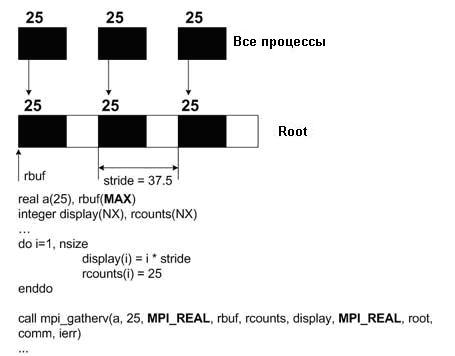
2.3.3 Gatherv
(гибкая сборка "переменный каждый-одному") и
Scatterv (гибкое размещение
"переменный один-каждому")
Функции MPI_Gatherv и MPI_Scatterv - это такие версии MPI_Gather и MPI_Scatter, которые могут работать с переменным размером сообщений. MPI_Gatherv расширяет функциональность MPI_Gather, изменяя получаемое count от целого числа до массива целых чисел и предоставляя новый аргумент displs (тоже массив). MPI_Gatherv позволяет использовать переменное значение для count каждого процесса. Эта функция также допускает гибкость в размещении собранных данных (данные передаются также и в корневой процесс). Как аналог MPI_Gatherv, MPI_Scatterv является расширением функции MPI_Scatter и находится в тех же самых отношениях к MPI_Scatter, что и MPI_Gatherv к MPI_Gather. Дополнительная информация по этому вопросу представлена в модуле MPI коллективный обмен сообщениями II.
C
|
|
|
|
|
|
Переменные для Gatherv:
|
sbuf |
- стартовый адрес буфера отправителя, |
|
scount |
- количество элементов в буфере отправки, |
|
stype |
- тип данных элементов буфера отправки, |
|
rbuf |
- стартовый адрес буфера получателя, |
|
rcount |
- массив, содержащий количество элементов, которые будут получены от каждого процесса, |
|
displs |
- массив, задающий смещение относительно rbuf (стартового адреса буфера получателя), в который помещаются входящие данные от соответствующего процесса, |
|
rtype |
- тип данных буфера получателя, |
|
root |
- ранг процесса получателя, |
|
comm |
- коммуникатор группы. |
Заметим, что rbuf, rcount, rtype имеют значение только для корневого процесса.
Переменные для функции Scatterv:
|
sbuf |
- адрес буфера отправителя, |
|
scount |
- массив целых чисел, определяющий количество элементов для отправки каждому процессу, |
|
displs |
- массив, определяющий смещение относительно sbuf, от которого берутся данные отправляемые к соответствующим процессам, |
|
stype |
- тип данных элементов буфера отправителя, |
|
rbuf |
- адрес буфера получателя, |
|
rcount |
- количество элементов в буфере получателя, |
|
rtype |
- тип данных элементов буфера получателя, |
|
root |
- ранг процесса отправителя и |
|
comm |
- коммуникатор группы |
Заметим, что sbuf, scount, stype имеют значение только для корневого процесса.
Для иллюстрации использования функций MPI_Gatherv и MPI_Scatterv ниже приведены два фрагмента программ на ФОРТРАНе:
MPI_Gatherv
MPI_Scatterv
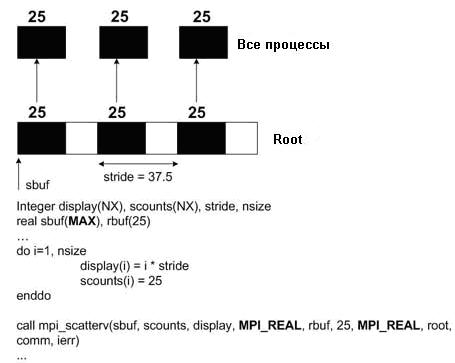
Нетрудно представить себе аналогичные фрагменты на С.
2.3.4 Allgather (всеобщая сборка "все-каждому")
MPI_Allgather отличается от MPI_Gather только тем, что все процессы, а не только корневой, получают результат. j-й блок буфера получателя является блоком данных, отправленных от j-го процесса. Подобные отношения верны как для MPI_Allgatherv, так и для MPI_Gatherv. Синтаксис MPI_Allgather и MPI_Allgatherv подобен MPI_Gather и MPI_Gatherv, соответственно. Однако, у MPI_Allgather и MPI_Allgatherv аргумент root отсутствет.
C
|
|
|
|
|
|
Переменные функции Allgather:
|
sbuf |
- стартовый адрес буфера отправителя, |
|
scount |
- количество элементов в буфере отправки, |
|
stype |
- тип данных элементов буфера отправки, |
|
rbuf |
- стартовый адрес буфера получателя, |
|
rcount |
- количество элементов, полученных от произвольного процесса, |
|
rtype |
- тип данных элементов буфера получателя, |
|
comm |
- коммуникатор группы. |
Заметим, что аргументы функции Allgather те же самые, что и у функций MPI_Gather или MPI_Gatherv за исключением того, что отсутствует аргумент root.
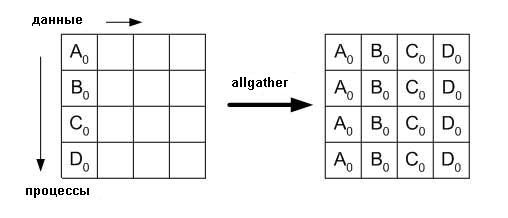
Пример:
- Умножение матрицы на вектор для матрицы, распределенной по строкам
- Необходимо подсчитать весь выходной вектор, поскольку он нужен для одного процесса
Типовой код
double a[100,25], b[100], cpart[25], ctotal[100];for(i=0;i<25;i++) { cpart[i]= 0;for(k=0;k<100;k++) { cpart[i]=cpart[i]+a[k,i]*b[k]; } } MPI_Allgather(cpart,25,MPI_REAL,ctotal,25,MPI_REAL,MPI_COMM_WORLD);
2.3.5 All to All (всеобщий обмен "каждый-каждому")
В приложениях, аналогичных транспонированию матрицы или быстрому преобразованию Фурье (БПФ), вызов MPI_Alltoall весьма полезен. Этот вызов по сути является расширением Allgather, в котором каждый процесс отправляет различные данные каждому получателю. j-й блок от i-го процесса принимается j-м процессом и сохраняется в i-м блоке. Графическое представление MPI_Alltoall показано ниже:
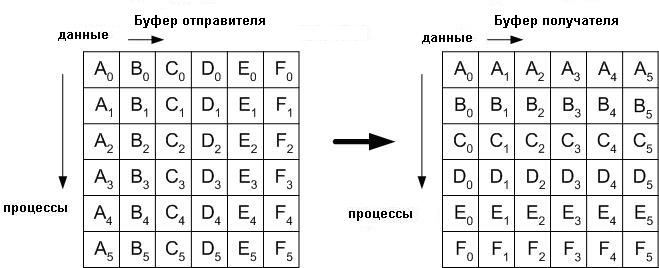
Синтаксис функции MPI_Alltoall имеет следующий вид:
C
|
|
|
Переменные функции Alltoall:
|
sbuf |
- стартовый адрес буфера отправителя, |
|
scount |
- количество элементов, отправленных каждому процессу, |
|
stype |
- тип данных элементов буфера отправки, |
|
rbuf |
- стартовый адрес буфера получателя, |
|
rcount |
- количество элементов, получаемых от любого процесса, |
|
rtype |
- тип данных элементов буфера получателя, |
|
comm |
- коммуникатор группы. |
Заметим, что те же самые спецификации, что и у Allgather, за исключением sbuf, должны содержать scount*NPROC элементов.
2.4 Функции глобальных вычислений
Существует два типа функций глобальных вычислений: приведение (reduce) и сканирование (scan). Функция операции, передаваемая процедуре глобального вычисления, является или предопределенной функцией MPI или функцией, написанной пользователем. MPI обеспечивает четыре функции глобальных вычислений. Пользователям также дана возможность использовать свои собственные функции. В начале этого раздела будут обсуждаться вычисление приведения (reduction computation). Далее √ вычисление сканирования (scan computation).
MPI_Reduce
Одна из самых полезных коллективных операций √ это глобальное приведение (global reduction) или операция объединения. Частичные результаты от каждого процесса группы объединяются в одном указанном процессе или всех процессах, при этом используется определенная функция. Если в группе процессов присутствует n процессов и D(i, j) - j-ый элемент данных в процессе i, то элемент данных Dj в корневом процессе, получается после применения функции приведения с помощью выражения:
Dj= D(0,j)*D(1,j)* ... *D(n-1,j)
где ⌠*■ обозначает функцию приведения, которая всегда предполагается ассоциативной. Все предопределенные функции MPI также предполагаются коммутативными. Можно определить функции, считая их ассоциативными, но не коммутативными. Каждый процесс может предоставлять один элемент или последовательность элементов. В обоих случаях операция объединения выполняется поэлементно на каждом элементе последовательности. Есть три версии операций приведения. Это √ MPI_Reduce, MPI_Allreduce, и MPI_Reduce_scatter. Форма этих элементарных операций приведения дана ниже:
C
|
|
|
|
|
|
|
|
|
Различия вышеперечисленных операций приведения в следующем:
- MPI_Reduce возвращает результаты единственному процессу;
- MPI_Allreduce возвращает результаты всем процессам данной группы;
- MPI_Reduce_scatter размещает вектор, получаемый из операции приведения, по всем процессам.
|
sbuf |
- стартовый адрес буфера отправителя, |
|
rbuf |
- стартовый адрес буфера получателя, |
|
count |
- количество элементов в буфере отправки, |
|
stype |
- тип данных элементов буфера отправки, |
|
op |
- операция приведения (которой может быть предопределенная в MPI операция или ваша собственная), |
|
root |
- ранг процесса получателя, |
|
comm |
- коммуникатор группы.. |
Замечания:
* rbuf имеет значение только для корневого процесса,
* аргумент rcounts в функции MPI_Reduce_scatter является массивом
Сканирование
Операция сканирования или префиксного приведения выполняет частичное приведение на распределенных данных. А именно, пусть n √ размер группы процессов, D (k,j) - j-й элемент данных в процессе k после возврата из сканирования, и d (k,j) - j-й элемент данных в процессе k перед сканированием. Пусть k =0, 1..., n-1. Сканирование возвращает
D(k,j) = d(0,j) * d(1,j) * ... *d(k,j)
где ⌠*■ обозначает функцию приведения, которая может быть либо предопределенной функцией MPI, либо функцией, определенной пользователем.
Синтаксис операции сканирования MPI:
C
|
|
|
|
sbuf |
- стартовый адрес буфера отправителя, |
|
rbuf |
- стартовый адрес буфера получателя, |
|
count |
- количество элементов во входном буфере, |
|
datatype |
- тип данных элементов во входном буфере, |
|
op |
- операция, |
|
comm |
- коммуникатор группы. |
Заметим, что сегментированное сканирование может быть проведено, если создана подгруппу для каждого сегмента.
Предопределенные операции приведения
Примеры предопределенных операций MPI перечислены в Таблице 1. MPI также предоставляет механизм для определяемых пользователями операций, используемых в MPI_Allreduce и MPI_Reduce.
|
Предопределенные операции приведения MPI |
|||
|
Название |
Значение |
C-тип |
FORTRAN-тип |
|
MPI_MAX |
maximum |
integer, float |
integer, real, complex |
|
MPI_MIN |
minimum |
integer, float |
integer, real, complex |
|
MPI_SUM |
sum |
integer, float |
integer, real, complex |
|
MPI_PROD |
product |
integer, float |
integer, real, complex |
|
MPI_LAND |
logical and |
integer |
logical |
|
MPI_BAND |
bit-wise and |
integer, MPI_BYTE |
integer, MPI_BYTE |
|
MPI_LOR |
logical or |
integer |
logical |
|
MPI_BOR |
bit-wise or |
integer, MPI_BYTE |
integer, MPI_BYTE |
|
MPI_LXOR |
logical xor |
integer |
logical |
|
MPI_BXOR |
bit-wise xor |
integer, MPI_BYTE |
integer, MPI_BYTE |
|
MPI_MAXLOC |
max value and location |
combination of int, float, double, and long double |
combination of integer, real, complex, double precision |
|
MPI_MINLOC |
min value and location |
combination of int, float, double, and long double |
combination of integer, real, complex, double precision |
Пример
- Каждый процесс в имитации динамики леса вычисляет максимальную высоту дерева для региона этого дерева.
- Процесс 0, который записывает результат, должен знать глобальный максимум высоты.
int maxht, globmx;
.
.
. (вычисления, которые определяют максимальную высоту)
. . MPI_Reduce (maxht, globmx, 1, MPI_INTEGER, MPI_MAX, 0, MPI_COMM_WORLD); if (taskid == 0) {.
. (Запись результата)
.
}
Операции, определяемые пользователем
- Пользователь может определить собственную операцию приведения
- Для этого можно воспользоваться MPI_Op_create
3. Проблемы эффективности работы
- Много скрытых коммуникаций связано с коллективной коммуникацией
- Эффективность работы сильно зависит от используемой реализации MPI
- Использование коллективной коммуникации не всегда оправдано, поскольку в принудительном порядке может быть использована синхронизация
3.1 Пример: Пересылки (broadcast) по 8 процессам
Пример двух подходов к реализации пересылки (broadcast)
Простой подход заключается в том, что один процесс пересылает одно и то же сообщение по всем остальным процессам по одному сообщению в каждый момент времени.
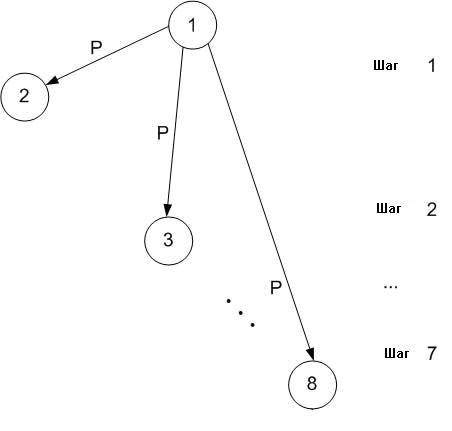
Количество переданных данных: (N-1)*p
N
= число процессов
p = размер сообщения
Число шагов: N-1
Более быстрый и остроумный подход заключается в том, чтобы позволить другим процессам помочь в распространении сообщения. На первом шаге процесс 1 отправляет сообщение процессу 2. На втором шаге могут участвовать уже оба процесса: процесс 1 отправляет сообщение процессу 3, в то время как процесс 2 отправляет процессу 4. Точно так же на третьем шаге четыре процесса (1, 3, 2, и 4) отправляют сообщение четырем оставщимся процессам (5, 6, 7, и 8).
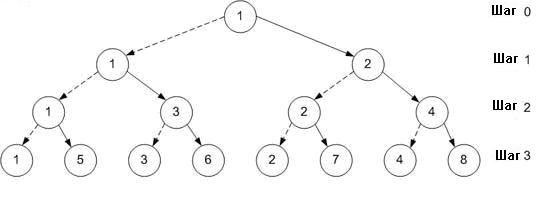
Жирная линия
обозначает пересылку данных
Пунктирная линия обозначает предыдущую передачу данных
Количество переданных данных: (N-1)*p
N
= число процессов
p = размер сообщения
Число шагов: log2N
Сравним число шагов для этих двух подходов:
Простой подход: N-1 шаг.
Более быстрый подход: log2N шагов.
Оценка количества шагов в более быстром подходе уменьшается по мере роста N.
3.2 Пример: Размещение по 8 процессам
Пример двух подходов к реализации размещения (scatter)
Простой подход заключается в том, что один процесс размещает N сообщений по другим процессам по одному сообщению в каждый момент времени.
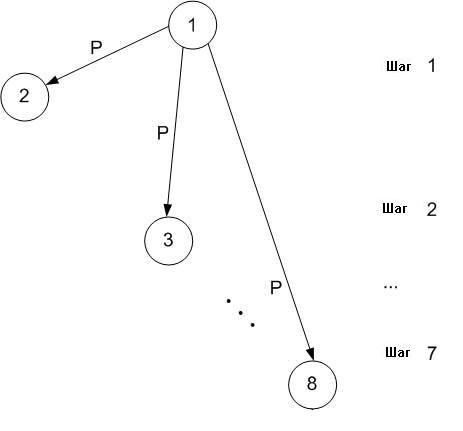
Количество переданных данных: (N-1)*p
N
= число процессов
p = размер сообщения
Число шагов: N-1
Более быстрый подход заключается в том, чтобы позволить другим процессам помочь в распространении сообщения. На первом шаге процесс 1 отправляет половину данных (размер 4*p) процессу 2. На втором шаге могут участвовать уже оба процесса: процесс 1 отправляет одну половину данных, которые он получил на шаге 1 (размер 2*p) процессу 3, в то время как процесс 2 отправляет другую половину данных, которые он получил на шаге 1, процессу 4. На третьем шаге четыре процесса (1, 3, 2, и 4) отправляют конечные сообщения (размера p) к оставшимся четырем процессам (5, 6, 7, и 8).
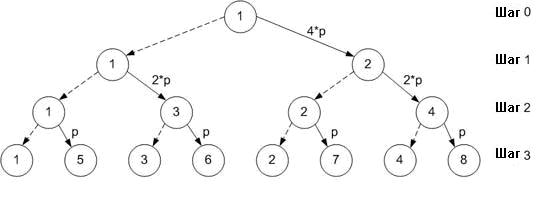
Жирная линия
обозначает пересылку данных
Пунктирная линия обозначает предыдущую передачу данных
Количество переданных данных: log2N * N * p/2
N
= число процессов
p = размер сообщения
Число шагов: log2N
Сравним число шагов для этих двух подходов:
Простой подход: N-1
Более быстрый подход: log2N
Оценка количества шагов в более быстром подходе уменьшается по мере роста N.
Литература
Книга
Using MPI: Portable Parallel Programming with the Message-Passing Interface, by William Gropp, Ewing Lusk, and Anthony Skjellum. Published 10/21/94 by MIT Press, 328 pages.
World Wide Web
- Домашняя страница MPI в Argonne National Labs http://www.mcs.anl.gov/mpi
- Netlib: MPI
- Параллельные вычисления LAM/MPI
- Модуль Основы программирования в MPI
- Модуль MPI попарные коммуникации I
Выборка программ, доступных в Internet, которые иллюстрируют команды, охваченные в этом модуле.
![]() Вопросы для проверки
усвоения материала
Вопросы для проверки
усвоения материала
![]() Лабораторная
работа
Лабораторная
работа
|
|
|
╘ 2003
Вычислительныйцентр им. А.А.Дородницына Все права защищены. |
|